When multiple sources of information produce different, possibly even superficially conflicting probabilities for the same event, the question arises as to how those probabilities should be treated. That is, different sources, or different experimental tests, could imply different probabilities for the same event. There’s no obvious objective solution to this problem, and as a practical matter, even a crude method, such as taking a simple average of the probabilities, will probably work just fine for something like determining the probabilities of a coin toss. However, when dealing with arbitrary data, perhaps even with no prior information about the mechanics that generated the data, such an approach is likely to eliminate too much information about the structure of the data itself, generating useless answers.
Any solution to this problem is really an answer to the question of how much weight we should ascribe to each probability. That is, whatever probability we ultimately arrive at as the “correct” answer can be expressed as a linear combination of the underlying probabilities, even if that’s not how we actually arrived at the correct answer. While this might seem like a trivial statement of algebra, it offers insight into the fundamental question that underlies any solution to this problem, which is, “how much attention should I pay to this piece of information?”
Shannon Coding
In 1948, Claude Shannon showed that there was a surprising connection between probability and information. Though he was arguably only trying to construct optimally short encodings for messages, he ended up uncovering a deep, and fundamental relationship between the nature of probability and information. To establish an intuition, consider the string x = (aaab), and assume that we want to encode x as a binary string. First we need to assign a binary code to each of a and b. Since a appears more often than b, if we want to minimize the length of our encoding of x, then we should assign a shorter code to a than we do to b. For example, if we signify the end of a binary code with a 1, we could assign the code 1 to a, and 01 to b. As such, our encoding of x would be 11101, and since x contains 4 characters, the average number of bits per character in our encoding of x is 5/4. Now consider the string x = (ab). In this case, there are no opportunities for this type of compression because all characters appear an equal number of times. The same would be true of x = (abcbca), or x = (qs441z1zsq), each of which has a uniform distribution of characters. In short, we can take advantage of the statistical structure of a string, assigning longer codes to characters that appear less often, and shorter codes to characters that appear more often. If all characters appear an equal number of times, then there are no opportunities for this type of compression.
Shannon showed that, in general, we can construct an optimally short encoding, without any loss of information, if we assign a code of length log(1/p) bits to a signal that has a probability of p. That is, if the frequency of a signal from a source is p, and we want to encode that source, then we should assign a code of length log(1/p) to the signal. It follows that if a source has N possible signals, and the probability of each signal is 1/N (i.e., the signals have a uniform distribution), then the expected code length of a signal generated by the source is log(N).
Resource Management and Human Behavior
Even though it is ultimately a human being that will assign a code to a signal, and therefore ascribe information to the signal, if we take a step back, we see that, using an optimal encoding, a low probability event carries more information than a high probability event. Moreover, Shannon’s coding method is objectively optimal, in that it is not possible to construct a better encoding without losing information (if we’re considering only the distribution of the signals). That is, a source generates signals, not information, but once a human being observes a source, a representational system is required if that person wants to record, or communicate, the signals generated by that source, which will produce information. As a result, though a human being must take the active steps of observing a source, and then encoding its signals, there is an objective component to the statement that low probability events carry more information than high probability events. This is consistent with common sense, and possibly even how our brains filter information. Put crudely, as an example, high probability stories are generally considered boring (e.g., “I went to my local pub last night”), whereas extraordinary, and unlikely tales generally garner a great deal of attention and inquiry (e.g., “I met a celebrity at my local pub last night”).
You could take the view that this is just an oddity of human nature, and that people prefer unusual tales. Alternatively, you could also take the view that it is instead the consequence of something much more profound about how our brains filter out the information that constantly bombards our senses. Specifically, it seems possible that our decisions allocate resources to the experiences most likely to generate the lowest probability signals, thereby maximizing our information intake. Without spending too much time on the topic, this view could explain why human beings are generally drawn towards things and experiences that are presented as exclusive, rare, or unusual, and less enthusiastic about things and experiences that are presented as common, or mundane. In this view, pretensions and preferences are the product of a rational resource management system that allocates the senses towards experiences that are most likely to maximize the amount of information observed.
Information and Probability
Returning to the original problem above, the probability of an event should then be a function of the probabilities implied by a data set, and the importance of each data point in our data set. For simplicity, let’s assume that we have total confidence in the data from which we derive our probabilities. That is, we’re assuming our data is free from errors and reflects events that actually occurred, and were properly measured and recorded.
Let’s begin with the classic example of a coin toss, and assume that 5 people are all tossing perfectly identical coins, 25 times each, and recording the results. If one of those 5 people came back and said that they had tossed 25 heads in a row, we would probably view that as extraordinary, but possible. Considering this person’s data in isolation, the observed probability of heads would be 1, and the observed probability of tails would be 0. In contrast, our ex ante expectation, assuming the coins were expected to be a fair, would have been that the probability of each of heads and tails is 1/2. Assuming that all of the other people come back with roughly equal probabilities for heads and tales, our outlier data set would assign a probability of 1 to an event that we assumed to have a probability of 1/2, and a probability of 0 to another event that we assumed to have a probability of 1/2.
Before we consider how much weight to ascribe to this “outlier” data, let’s consider another case that will inform our method. Now assume that instead, 4 out of the 5 people report roughly equal probabilities for heads and tails, whereas one person reports back that their coin landed on its side 13 times out of 25 tosses, and that the remaining tosses we’re split roughly equally between heads and tails. That is, rather than landing on heads or tails, the coin actually landed on its side 13 times. This is an event that is generally presumed to have a probability of 0, and ignored. So upon hearing this piece of information, we would probably be astonished (recall that we are not calling the data itself into question). That is, something truly incredible has happened, since an event that has a probability of effectively zero has in fact happened 13 times. Considering the data reported by this person in isolation, we’d have an event that generally has an ex ante probability of 0 being assigned an observed probability of about 1/2, and then two events that typically have an ex ante probability of 1/2 being assigned observed probabilities of about 1/4.
Now ask yourself, which is more remarkable:
(1) the first case, where the person reported that an event with an ex ante probability of 1/2 had an observed probability of 1; or
(2) the second case, where the person reported that an event that had an ex ante probability of 0 had an observed probability of 1/2?
Though the magnitude of the difference between the ex ante probability and the observed probability is the same in both cases, the clear answer is that the second case is far more surprising. This suggests an inherent asymmetry in probabilities that are biased towards low probability events. That is, “surprisal” is not a function of just the difference between the expected probability and the observed probability, but also of the probability itself, with low probability events generating greater “surprisal”.
If we return to Shannon’s formula for the optimal code length for a signal, we see this same asymmetry, since low probability signals are assigned longer codes than high probability signals. This suggests the possibility that we can mirror surprisal in observations by weighting probabilities using the information content of the probability itself. That is, we can use the optimal code length for a signal with a given probability to inform our assessment as to how important the data underlying a particular reported probability is.
Under this view, the reports generated by the people flipping coins will contain different amounts of information. The more low probability events a given report contains, the greater the information contained in the report, implying that data that describes low probability events quite literally contains more information than data that describes high probability events. As a result, we assume that for a given event, the data underlying a low reported probability contains more information than the data underlying a high reported probability.
Information-Weighted Probabilities
Rather than simply weight the probabilities by their individual code lengths (which might work just fine in certain contexts), I’ve been making use of a slightly different technique in image recognition, which looks at how much the information associated with a given data point deviates from the average amount of information contained across all data points in the data set. Specifically, the algorithm I’ve been making use of partitions an image into equally sized regions, with the size of the region adjusted until the algorithm finds the point at which each region contains a maximally different amount of information. That is, for a given region size, the algorithm measures the average entropy of each region (by analyzing the color distribution of each region), and then calculates the standard deviation of the entropies over all regions. It keeps iterating through region sizes until it finds the size that maximizes the standard deviation of the entropies over all regions. This ends up working quite well at uncovering structure in arbitrary images with no prior information, with the theory being that if two regions within an image contain legitimately different features, then they should contain objectively different quantities of information. By maximizing the information contrast of an image, under this theory, we maximize the probability that each region contains a different feature than its neighboring regions. I then have a second algorithm that is essentially an automata “crawl” around the image and gather up similar regions (see the paper entitled, “A New Model of Artificial Intelligence” for more on this approach).
By analogy, if we have a set of probabilities, 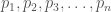

Specifically, we calculate the weight for each probability as follows:

That is, we take the variance and add 1 to it, producing a set of weights that are greater than or equal to 1. This produces a probability given by the weighted sum,

where 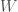
This formulation gives greater weight to outlier probabilities than those that are closer to the average probability, but because we begin with the code length associated with each probability, and not the probability itself, we overstate outlier low probabilities more than outlier high probabilities. That is, this method reflects our observations above, that events that have lower probabilities generate more surprisal, and therefore, “get more attention” in this method. Put differently, this method balances both (1) how “unusual” a data point is compared to the rest of the data set, and (2) how much information went into generating the data point. Since lower probability events are generated by data that contains more information (which is admittedly an assumption of this model), unusual low probabilities are given more weight than unusual high probabilities, and average probabilities have the same, minimum weight.
For example, the information weighted probability of the probabilities {.8 .8 .05} is 0.47. In contrast, the simple average of those probabilities is .55.
Note that this method doesn’t require any ex ante probabilities at all, so the question of what “prior” probability to use is moot. That is, this method takes the data as it is, with no expectations at all, and generates a probability based upon the assumed information content of the data that generated each probability. As a result, this method could be useful for situations where no prior information about the data is available, and we are forced to make sense of the data “in a vacuum”.



