The fundamental observation underlying all of information theory is that probability and information are inextricably related to one another through Shannon’s celebrated equation,
I = log(1/p),
where I is the optimal code length for a signal with a probability of p. This equation in turn allows us to measure the information content of a wide variety of mathematical objects, regardless of whether or not they are actually sources that generate signals. For example, in the posts below, I’ve shown how this equation can be used to evaluate the information content of an image, a single color, a data set, and even a particle. In each of these instances, however, we evaluated the information content of a definite object, with known properties. In this post, I’ll discuss how we can measure the information content of a message that conveys partial information about an uncertain event, in short, answering the question of, “how much did I learn from that message?”
Exclusionary Messages
Let’s begin with a simple example. Consider a three-sided dice, with equally likely outcomes we’ll label A, B, and C. If we want to efficiently encode and record the outcomes of some number of throws, then Shannon’s equation above implies that we should assign a code of length log(3) bits to each of the three possible outcomes.
Now imagine that we have received information that guarantees that outcome A will not occur on the next throw. This is obviously a hypothetical, and in reality, it would generally not be possible to exclude outcomes with certainty in this manner, but let’s assume for the sake of illustration that an oracle has informed us that A will not occur on the next throw. Note that this doesn’t tell us what the next throw will be, since both B and C are still a possibility. It does, however, provide us with some information, since we know that the next throw will not be A.
Now imagine that, instead, our oracle told us that the next throw is certain to be A. That is, our oracle knows, somehow, that no matter what happens, the next throw will be A. In this case, we have specified a definite outcome. Moreover, this outcome has a known ex ante probability, which in turn implies that it has an information content. Specifically, in this case, the probability of A is 1/3, and its information content is log(3) bits. Since learning in advance that A will occur is not meaningfully distinguishable from actually observing A (at least for this purpose), upon learning that A will be the next outcome, we receive log(3) bits of information. As a result, we receive log(3) bits of information upon receipt of the message from our oracle, and learn nothing at all upon throwing the dice, since we already know the outcome of the next throw. Note that this doesn’t change the total amount of information observed, which is still log(3) bits. Instead, the message changes the timing of the receipt of that information. That is, either we receive log(3) bits from the oracle, or we observe log(3) bits upon throwing the dice. The only question is when we receive the information, not how much information we receive.
Now let’s return to the first case where our oracle told us that the outcome will definitely not be A. In this case, our oracle has excluded an event, rather than specified a particular event. As a result, we cannot associate this information with any single event in the event space, since two outcomes are still possible. We call this type of information an exclusionary message, since it excludes certain possibilities from the event space of an uncertain outcome. As a general matter, any information that reduces the set of possible outcomes can be viewed as an exclusionary message. For example, if instead our oracle said that the next outcome will be either B or C, then this message can be recharacterized as an exclusionary message conveying that A will not occur.
If we receive an exclusionary message that leaves only one possible outcome for a particular trial, then the information content of that message should equal the information content of observing the actual outcome itself. Returning to our example above, if our oracle tells us that B and C will not occur upon the next throw, then that leaves A as the only possible outcome. As a result, knowing that neither of B and C will occur should convey log(3) bits of information. Therefore, intuitively, we expect an exclusionary message that leaves more than one possible outcome remaining to convey less than log(3) bits of information. For example, if our oracle says that B will not occur, then that message should convey fewer than log(3) bits, since it conveys less information than knowing that neither of B and C will occur.
As a general matter, we assume that the information content of an exclusionary message that asserts the non-occurrence of an event that otherwise has a probability of p of occurring is given by,
I = log(1/(1-p)).
The intuition underlying this assumption is similar to that which underlies Shannon’s equation above. Specifically, an event with a high ex ante probability that fails to occur carries a great deal of surprisal, and therefore, a great deal of information. In contrast, a low probability event that fails to occur carries very little surprisal, and therefore, very little information. Note that, as a result, the information content of an exclusionary message will depend upon the ex ante probability for the event excluded by the message, which is something we will address again below when we consider messages that update probabilities, as opposed to exclude events.
Returning to our example, if our oracle informs us that A will not occur on the next throw, then that message conveys log(3/2) bits of information. Upon receipt of that message, the probabilities of B and C should be adjusted to the conditional probabilities generated by assuming that A will not occur. In this case, this implies that B and C each have a probability of 1/2. When we ultimately throw either a B or a C, the total information received from the message and observing the throw is log(3/2) + log(2) = log(3) bits. This is consistent with our observation above that the oracle does not change the total amount of information received, but instead, merely changes the timing of the receipt of that information.
If instead our oracle informs us that neither of A and B will occur, then that message conveys log(3) bits of information, the same amount of information that would be conveyed if our oracle told us that C will occur. This is consistent with our assumption that the amount of information contained in the message should increase as a function of the number of events that it excludes, since this will eventually lead to a single event being left as the only possible outcome.
If we receive two separate messages, one informing us of the non-occurrence of A, and then another message that informs us of the non-occurrence of B, both received prior to actually throwing the dice, then this again leaves C as the only possible outcome. But, we can still measure the information content of each message separately. Specifically, the first message asserts the non-occurrence of an event that has a probability of 1/3, and therefore, conveys log(3/2) bits of information. The second message, however, asserts the non-occurrence of an event that has a probability of 1/2 after receipt of the first message. That is, after the first message is received, the probabilities of the remaining outcomes are adjusted to the conditional probabilities generated by assuming that A does not occur. This implies that upon receipt of the second message, B and C each have a probability of 1/2. As a result, the second message conveys log(2) bits of information, since it excludes an outcome that has a probability of 1/2. Together, the two messages convey log(3/2) + log(2) = log(3) bits of information, which is consistent with our assumption that whether a message identifies a particular outcome, or excludes all outcomes but one, then the same amount of information should be conveyed in either case.
As a general matter, this approach ensures that the total information conveyed by exclusionary messages and through observation is always equal to the original ex ante information content of the outcome that is ultimately observed. As a result, this approach “conserves” information, and simply moves its arrival through time.
As a general matter, when we receive a message asserting the non-occurrence of an event with a probability of p*, then we’ll update the remaining probabilities to the conditional probabilities generated by assuming the non-occurrence of the event. This means all remaining probabilities will be divided by 1 – p*. Therefore, the total information conveyed by the message followed by the observation of an event with a probability of p is given by,
log(1/(1-p*)) + log((1-p*)/p) = log(1/p).
That is, the total information conveyed by an exclusionary message and any subsequent observation is always equal to the original ex ante information content of the observation.
Partial Information and Uncertainty
This approach also allows us to measure the information content of messages that don’t predict specific outcomes, but instead provide partial information about outcomes. For example, assume that we have a row of N boxes, each labelled 1 through N. Further, assume that exactly one of the boxes contains a pebble, but that we don’t know which box contains the pebble ex ante, and assume that each box is equally like to contain the pebble ex ante. Now assume that we receive a message that eliminates the possibility that box 1 contains the pebble. Because all boxes are equally likely to contain the pebble, the information content of that message is log(N/N-1). Now assume that we receive a series of messages, each eliminating one of the boxes from the set of boxes that could contain the pebble. The total information conveyed by these messages is given by,
log(N/(N-1)) + log((N-1)/(N-2)) + … + log(2) = log(N).
That is, a series of messages that gradually eliminate possible locations for the pebble conveys the same amount of information as actually observing the pebble. Note that simply opening a given box would constitute an exclusionary message, since it conveys information that will either reveal the location of the pebble, or eliminate the opened box from the set of possible locations for the pebble.
As a general matter, we can express the uncertainty as to the location of the pebble as follows:
U = Log(N) – I.
Messages that Update Probabilities
In the previous section, we considered messages that exclude outcomes from the event space of a probability distribution. In practice, information is likely to come in some form that changes our expectations as to the probability of an outcome, as opposed to eliminating an outcome as a possibility altogether. In the approach we developed above, we assumed that the information content of the message in question is determined by the probability of the event that it excluded. In this case, there is no event being excluded, but instead, a single probability being updated.
Let’s begin by continuing with our example above of the three-sided dice and assume that we receive a message that updates the probability of throwing an A from 1/3 to 1/4. Because the message conveys no information about the probabilities of B and C, let’s assume that their probabilities maintain the same proportion to each other. In this particular case, this implies that each of A and B have a probability of 3/8. Though its significance is not obvious, we can assume that the updated probabilities of A and B are conditional probabilities, specifically, the result of division by a probability, which in this case would be 8/9. That is, in our analysis above, we assumed that the remaining probabilities are adjusted by dividing by the probability that the excluded event does not occur. In this case, though there is no event being excluded, we can, nonetheless, algebraically solve for a probability, division by which, will generate the updated probabilities for the outcomes that were not the subject of the message.
Continuing with our example above, the message updating the probability of A from 1/3 to 1/4 would in this case have an information content of log(9/8). Upon observing either B or C after receipt of this message, the total information conveyed would be log(9/8) + log(8/3) = log(3). Note that information is not conserved if we were to subsequently observe A, but this is consistent with our analysis above, since throwing an A after receipt of an exclusionary message regarding A would imply that we’ve observed an infinite amount of information.
Interestingly, this approach implies the existence of a probability, the significance of which is not obvious. Specifically, if we receive a message with an information content of i, then since,
i = log(1/1 – p),
the probability associated with that information is given by,

This is the same form of probability we addressed in the post below, “Using Information Theory to Explain Color Perception”. In the analysis above, this was the probability of an event excluded by a message. If we assume that, similarly, in this case, this is the probability of some event that failed to occur, then the information content of the message would again increase as a function of surprisal, with high probability events that fail to occur carrying more information than low probability events.
We can still make use of this probability to inform our method, even though we don’t fully understand its significance. Specifically, this probability implies that messages that update probabilities always relate to probabilities that are reduced. That is, just like an exclusionary message eliminates an event from the outcome space, a message that updates a probability must always be interpreted as reducing the probabilities of some outcomes in the event space, meaning that the conditional probabilities of the outcomes that are not the subject of the message will be increased. Since we divide by 1 – p to generate those conditional probabilities, assuming that the conditional probabilities decrease implies that the probability 1 – p > 1, which in turn implies that p < 0. As a result, assuming that p is in fact a probability provides insight into our method, regardless of whether or not we fully understand the significance of the probability.
For example, if we receive a message that increases the probability of A to 2/3, then we would interpret that message as decreasing the probability of both B and C to 1/6. That is, we recharacterize the message so that the subject of the message is actually outcomes B and C. Recall that we determine p by looking to the conditional probabilities of the outcomes that are not the subject of the message, and so in this case, we have (1/3)/(1-p) = 2/3, which implies that 1 – p = 1/2. Therefore, the information content of the message is log(2), and upon observing an A, the total information received is log(2) + log(3/2) = log(3), i.e., the original ex ante information content of the outcome A.
 ,
,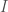 is the optimal code length (measured in bits) of a signal with a probability of p. In this particular case, the ultimate goal is to take an RGB color vector, map it to a probability, and from that, generate a code length using the equation above that we will treat as the information content of the color represented by the RGB vector (see the posts below for more on this approach).
is the optimal code length (measured in bits) of a signal with a probability of p. In this particular case, the ultimate goal is to take an RGB color vector, map it to a probability, and from that, generate a code length using the equation above that we will treat as the information content of the color represented by the RGB vector (see the posts below for more on this approach). that can be easily interpreted (at least mathematically) as a probability. But upon examination, we’ll see that this approach is unsatisfying from a theoretical perspective.
that can be easily interpreted (at least mathematically) as a probability. But upon examination, we’ll see that this approach is unsatisfying from a theoretical perspective. is measure of luminosity that we intend to map to a probability. Luminosity is an objective unit of measurement that does not depend upon its source. As a result, the probability we assign to x should similarly not depend upon the particular source we’re making use of, if we want our method to be objective. That is, a particular level of luminosity should be associated with the same probability regardless of the source that is generating it.
is measure of luminosity that we intend to map to a probability. Luminosity is an objective unit of measurement that does not depend upon its source. As a result, the probability we assign to x should similarly not depend upon the particular source we’re making use of, if we want our method to be objective. That is, a particular level of luminosity should be associated with the same probability regardless of the source that is generating it.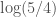 . Now imagine that we have a group of 10 identical light bulbs bundled together. On this device, using 4 of the lights produces a probability of 4/10, and a code length of
. Now imagine that we have a group of 10 identical light bulbs bundled together. On this device, using 4 of the lights produces a probability of 4/10, and a code length of  . In both cases, the luminosity generated would be the same, since in both cases, exactly 4 lights are on. This implies that, as a general matter, if we use this approach, our code lengths will depend upon the particular light source used, and will, therefore, not be an objective mapping from luminosity to probability.
. In both cases, the luminosity generated would be the same, since in both cases, exactly 4 lights are on. This implies that, as a general matter, if we use this approach, our code lengths will depend upon the particular light source used, and will, therefore, not be an objective mapping from luminosity to probability.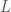 should be given by,
should be given by, ,
, is a constant that represents the length of the code for perceiving light.
is a constant that represents the length of the code for perceiving light. is not the information content of a Shannon code. Instead,
is not the information content of a Shannon code. Instead,  .
. (ignoring the constant term
(ignoring the constant term  back into Shannon’s original equation, we obtain the following:
back into Shannon’s original equation, we obtain the following: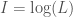 .
.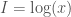 .
.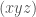 . The total luminosity of the vector is simply
. The total luminosity of the vector is simply 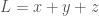 . As a result, we can construct a distribution of luminosity given by,
. As a result, we can construct a distribution of luminosity given by, .
.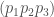 , which will give us a measure of the diffusion of the luminosity across the three channels. The maximum diffusion occurs when each channel has an equal amount of luminosity, which will produce no color at all, and scale from black to white, suggesting that color itself is the perceptual result of asymmetry in the distribution of information across wavelengths of light. In short, a high entropy color contains very little color information, and a low entropy color contains a lot of color information.
, which will give us a measure of the diffusion of the luminosity across the three channels. The maximum diffusion occurs when each channel has an equal amount of luminosity, which will produce no color at all, and scale from black to white, suggesting that color itself is the perceptual result of asymmetry in the distribution of information across wavelengths of light. In short, a high entropy color contains very little color information, and a low entropy color contains a lot of color information. as follows:
as follows: ,
, ,
, and
and 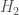 are the respective entropies of
are the respective entropies of  .
.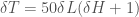 .
.

 . As you can see, the colors become more similar as we traverse the color bar from left to right, despite the fact that their distances in Euclidean space are constant.
. As you can see, the colors become more similar as we traverse the color bar from left to right, despite the fact that their distances in Euclidean space are constant.

