Attached is an updated draft of my second book, “Kate”:
Enjoy!
In a previous article, I introduced a vectorized polynomial interpolation algorithm that is extremely efficient, generating reasonably accurate interpolations of functions in about one to three seconds. You can of course refine the results, which I discussed as well, but the point being, that by using vectorization, we can turn what are otherwise brute force techniques, into elegant and efficient solutions to problems in computing.
I realized that you could take a similar approach to problems that are by their nature distributed, making use of a large number of linear approximations. For example, imagine a gas expanding in a volume, and assume that you want to predict the density in the regions over time. You could subdivide the volume into equally sized cubes, and then use a series of linear equations to predict the densities in each cube. Specifically, if we have 

This can be done using almost exactly the same code I introduced in the previous article. However, if 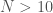

You could of course repeat this process, adding a constant term, or perhaps higher dimensional terms, creating quadratics, cubics, and other higher dimensional approximations, if necessary, for accuracy. Simply fix the coefficients obtained from the first application, and repeat the same process, generating a large number of possible coefficients for the higher or lower dimensions terms.
An additional upside to this approach is the fact that evaluating a polynomial is also vectorized in Octave, an example of which is included in the code I introduced in the previous article. This implies that evaluating the behavior of a system like an expanding gas, or a moving fluid, can be implemented in a distributed manner, which is not only more efficient, but realistic, in that the parts of a system that aren’t physically proximate, are probably independent, at least in the short run.
I just came to a very strange realization:
The amount of time you measure, depends upon your scale of observation.
To understand why this is the case, imagine you spill ink into a single sheet of paper. Now divide the paper into a grid, of equally sized boxes, and count the number of ink molecules in each box over time as the ink stain spreads.
Now imagine the ink stain is your clock.
This is realistic, in that it’ll take time for the stain to spread, and so you could measure time by measuring the distribution of the ink among the boxes over time. Said otherwise, as the ink spreads, the amount of time that passes increases. But we can formalize this by measuring the entropy of the ink stain in the grid. Specifically, the ink stain begins in exactly one box, producing an entropy of zero, since it is the entropy of a distribution over a single event, with a probability of one.
Eventually, the ink should be roughly uniformly distributed among the boxes, producing the maximum possible entropy. As a result, the entropy of the distribution of the ink stain is a measure of time. However, what’s truly bizarre about this, is that the amount of time you measure in this model depends upon the dimensions of the grid.
Just imagine a grid with one box –
That’s a clock that never moves, since the ink is always on the page, and therefore, the entropy is always zero. This is actually profound, and shows that if you want to truly distinguish between moments in time, you need a system that can be in a large number of states. For example, a normal clock repeats every 24 hours, but it’s supplemented by a day, month, and year, to distinguish it from other positions in time. More formally, a calendar is a system that has an infinite number of states. And you can’t truly tell time without such a system, otherwise you’ll end up labelling two different moments with the same name.
That said, calendars are only conceptually infinite, but are practically finite, because human beings live finite lives, and even the human species itself has been around for only some finite amount of time. It follows that unless the Universe itself is capable of being in an infinite number of states, it will eventually repeat the same state. Said otherwise, the state of the Universe as a whole is a clock, and if it’s only capable of being in some finite number of states, then by definition, eventually, if time itself is infinite, the same exact state of the Universe must happen twice.
I’ve written an algorithm that vectorizes polynomial interpolation, producing extremely fast approximations of functions. The algorithm works by generating all possible polynomials of a given degree, and then evaluates all of them, but because these operations are vectorized, the runtime is excellent, even on a home computer.
As a practical matter, the runtime is of course sensitive to the algorithm’s parameters, which are (x) the number of possible values for each coefficient, and (y) the degree of the polynomial.
The polynomial is expressed as follows:
The algorithm works by quantizing the possible values of each ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)
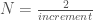


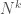
This algorithm then evaluates every resultant polynomial at every point in the domain, and selects the polynomial that produces the least total error, when compared to the range of the function.
Ordinarily, this would be an incredibly inefficient approach, but because all of these steps can be vectorized, the runtime is excellent, and on a sufficiently parallel machine, each step could be fully vectorized, likely allowing for basically instantaneous testing of every possible polynomial.
Running on an iMac, the algorithm generates and tests 160,000 fourth-degree polynomials in 2.38 seconds, and the best curve is shown below in green, together with the original sin curve in blue.

The algorithm generates and tests 160,000 linear approximations in 1.06 seconds, with the results shown below.

Note that increasing the degree of the polynomial of course increases the number of coefficients, and therefore, the number of possible polynomials. As a result, higher degree polynomials effectively include all possible lower degree polynomials, since any coefficient could be approximately or exactly zero. For example, using a fourth-degree polynomial could produce a roughly straight line. Therefore, the degree of the polynomial will of course impact the runtime on an ordinary machine. But nonetheless, even ordinary machines are clearly capable of vectorized computing, making this approach useful for essentially every modern device.
However, this is just a first step, and the real point of this algorithm is that it can be used as an operator in a more elaborate optimization algorithm. For example, rather than simply terminate after this one step, you could instead analyze the results, and repeat the process on some subset of the polynomials generated and tested. One obvious additional step would be to include linear terms that adjust the position of the curve along the x-axis:
We could apply the exact same process to the linear terms 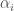
As a general matter, you could take the view that this approach is similar to a Monte Carlo approach, but I would disagree, since this process is deterministic, and covers a complete range of values, at a given level of granularity, and is therefore, not random at all, but is instead deterministic. It is in my opinion the same approach I use to A.I. generally: select a scale of granularity in observation or discernment, and then use vectorization to the maximum extent possible, to solve the problem at that scale. Said otherwise, first compress the problem to a tractable space, and then use vectorization to solve the problem in that space.
All that said, this approach can be easily adapted to a Monte Carlo method, by simply generating random values of each
Obviously, you could also use this for classifications, by applying 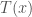
Octave Code:
I’ve assembled a significant amount of my work on A.I. and physics into a single book on the applications of discrete mathematics, that I’ll continue to update episodically in my free time.
Enjoy!
I’ve assembled all of my work on physics into a single book, that together unifies basically all of known physics.
Enjoy!


