In a previous article, I introduced a rigorous method for thinking about partial information, though for whatever reason, I left out a rather obvious corollary, which is that you can quantify both uncertainty and knowledge in terms of information, though I did go on a rant on Twitter, where I explained the concept in some detail.
Though I’ve done a ton of work on the issue, which I’ll expand upon in other articles, the fundamental equation that follows is,
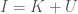 ,
,
Where 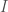 is the total information of the system,
is the total information of the system,  is the subjective knowledge with respect to the system, held by some observer, and
is the subjective knowledge with respect to the system, held by some observer, and  is the uncertainty of that same observer with respect to the system, all having units of bits.
is the uncertainty of that same observer with respect to the system, all having units of bits.
To develop an intuition for the equation, consider a set of  labeled boxes, one of which contains a pebble. The system of the boxes and single pebble can be in any one of states, since the pebble can be in any one of the boxes, with each such configuration representing a unique state of the system. As a storage device, the system can be in any one of states, and can, therefore, store
labeled boxes, one of which contains a pebble. The system of the boxes and single pebble can be in any one of states, since the pebble can be in any one of the boxes, with each such configuration representing a unique state of the system. As a storage device, the system can be in any one of states, and can, therefore, store  bits of information.
bits of information.
I am plainly making the assumption that this is the correct measure of the information content of the system as described. What cannot be debated is the fact that the system, as described, can be used to store bits. Moreover, as a general matter, the storage capacity of any system is always given by the logarithm of the number of states of the system, and so, though there could be other useful measures of the information content of a physical system, the log of the number of states of the system is both objectively, and physically meaningful.
Returning to the example of the pebble in one of boxes, imagine you have no information at all about which box contains the pebble, and no knowledge of the probabilities that the pebble is in a given box. In this case, your knowledge is exactly zero, and so your uncertainty is maximized at . If we increase , we increase your uncertainty, which as a practical matter, is exactly what would happen, since you now have more possible outcomes. Stated more formally, the system can be in a greater number of states, which as a mathematical and practical matter, increases your uncertainty with respect to the system.
You can read through the previous article to understand the mathematics of how knowledge changes as a function of observation and receipt of information, but the intuition is straightforward: learning about a system eliminates possible states of the system. For example, if I tell you that the pebble is in the first box, then it isn’t in the rest of them, and your uncertainty drops to zero. If I tell you that the pebble isn’t in the first box, then your uncertainty decreases, but is still greater than zero.
Now imagine there are  pebbles, and boxes, for some
pebbles, and boxes, for some  . It follows that this system can be in
. It follows that this system can be in  states. Intuitively, your uncertainty should follow the arc of the binomial coefficient, as a function of , increasing for some time, and then eventually decreasing again past
states. Intuitively, your uncertainty should follow the arc of the binomial coefficient, as a function of , increasing for some time, and then eventually decreasing again past  . Again, this causes the measure of uncertainty introduced above to change in a manner that is consistent with intuition, in that the more states a system can be in, the greater your uncertainty is with respect to the system.
. Again, this causes the measure of uncertainty introduced above to change in a manner that is consistent with intuition, in that the more states a system can be in, the greater your uncertainty is with respect to the system.
In Shannon’s original paper, in addition to introducing entropy as a measure of minimum average encoding length, he also proved that the equation satisfies a sensible definition of uncertainty. If you apply this idea to physical systems, what you end up with is an equivalence between the minimum average code length required to represent the system, and the uncertainty of an observer with respect to the system.
Again, these are assumptions that make use of underlying mathematical theorems, and are not theorems in and of themselves. Said otherwise, you could argue that physical uncertainty is not appropriately measured by the Shannon entropy, or the ideas I’ve introduced above, and in the previous article, which is fine. My goal is to present a practical measure of uncertainty, that moves in the correct direction, as a function of observation, and receipt of information, understanding that it may not even be possible to prove a physical claim of this type in any decisive manner.
It follows that if is the number of states of the system, then simply substituting uncertainty with Shannon’s equation for entropy, we have,
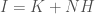 ,
,
where  .
.
So just a matter of simple algebra, we have that,
 .
.
This is consistent with intuition, in that as the entropy of a probability distribution decreases, you have more knowledge about the behavior of the system ex ante. In the extreme case, where the system is almost certain to be in a particular state, you have almost perfect knowledge about its behavior, since you can reliably expect it to be in that particular state.
Returning to the example above, let’s assume that the pebble is almost certain to be in the first box. This implies that the entropy of the probability distribution of the location of the pebble will be approximately zero, which in turn implies almost perfect knowledge about the system. This is consistent with intuition, since you can reasonably expect the pebble to be in the first box, basically all the time.
