I just saw an airplane turn on my walk home, and it dawned on me how strange it is that a machine can change its own velocity, which you could argue is a consequence of how I think about time. Specifically, I think about time as a set of possible outcomes along a discrete graph, simply because it’s a practical way to think about how a system can change, especially if you’re writing software to model its behavior. That is, if the system is in a given state, then there is some set of possible next states, and so on, which will produce a discrete graph. I happen to think that time is actually physically structured this way, but what’s relevant for this discussion, is that you can certainly model time as a discrete graph, as a practical matter.
Returning to the airplane, when it’s heading straight ahead, there will be some set of possible next states for the airplane’s motion at any given moment. But if the airplane were an ordinary projectile, this would not be the case, macroscopically, and instead, it would have a simple parabolic trajectory that would be unchangeable, absent intervention. So an ordinary projectile moving through space near Earth, doesn’t really have an interesting path through time, but is instead deterministic, at least at our scale of observation, absent intervention. In contrast, because an airplane can turn, increase velocity, or perhaps tilt, at any given moment, the next moment in time could always be some legitimately different state, leading to a multiplicity of possible paths through time, representing the future outcomes that are possible at any given moment.
As an example, let’s assume the plane is flying itself, which is realistic, and during the flight, the plane responds to some weather data, that causes it to change its course, turning the plane in a particular direction. Tracing the events that lead to this outcome, we have an exogenous event, which is the weather itself, then we have the systems within the airplane, receiving a signal representing the change in the weather, and then a response in the software piloting the plane, and ultimately the physical mechanisms of the plane itself, within the engines and the wings, responding to the software’s instructions.
It’s not as if any of this violates the conservation of momentum, since the plane is powered by fuel and electricity, to which there’s no magic, though the plane’s role in this set of facts requires electrical and mechanical energy to be already extant within the plane, in order for it to first receive the transmission, calculate the appropriate response, and then physically execute that response. However, what is in my opinion fascinating, upon reflection, is that the ability of systems of this type to respond to exogenous signals, allows these systems to have complex paths through time, that are contingent upon information that is exogenous to the system. In this case, even when piloting itself, the airplane can effectively decide to change directions, meaning that at any given moment, its path through time is very different from any ordinary, inanimate projectile.
All systems can of course be accelerated by exogenous momentum, which is typically a collision. But this is different: this is instead the case of a system that is ultimately accelerated by an exogenous piece of information. It is ultimately the ability to respond to information about an environment that makes the path of a system like this through time fundamentally different from any inanimate system. Though airplanes are obviously distinguishable from living systems, what I suppose I never fully appreciated, is that they arguably have more in common, in terms of their behavior through time, with living systems, than inanimate systems, since they are capable of acceleration that is contingent upon exogenous information.
To make it perfectly clear, we can distinguish between, for example, the position of the wheel of a car, and the information transmitted to the airplane: the position of a wheel is a physical state of the car itself, whereas the transmission regarding the weather is a representation of the state of an exogenous system, that is transmitted to the plane, that in turn causes a response within the plane itself. The point being, that a plane can respond to a representation of the state of an exogenous system, which really is the ability to autonomously respond to information, as opposed to being accelerated by some circumstance physically connected to the plane.
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=444444&s=0&c=20201002) for a function
for a function  , and that the function can be calculated (i.e., it is known to the algorithm). Further, assume we also have a known goal value
, and that the function can be calculated (i.e., it is known to the algorithm). Further, assume we also have a known goal value  (e.g., a zero of the function). The purpose of this algorithm is to find the domain value
(e.g., a zero of the function). The purpose of this algorithm is to find the domain value 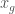 that generates the goal value
that generates the goal value  .
. at random points in the domain, which will produce a set of
at random points in the domain, which will produce a set of  for which
for which 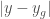 is minimum, where
is minimum, where 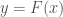 . That is, you select the domain value that generates a range value that is closest to the goal value.
. That is, you select the domain value that generates a range value that is closest to the goal value. is the average difference between the range values and the goal value over the domain values selected. That is, we calculate the difference between each range value
is the average difference between the range values and the goal value over the domain values selected. That is, we calculate the difference between each range value 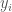 and the goal value
and the goal value 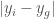 , and calculate the average over those differences.
, and calculate the average over those differences.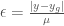 .
. allows us to compare the difference between the distance from our best range value and the goal value, and the average distance between range values and the goal value.
allows us to compare the difference between the distance from our best range value and the goal value, and the average distance between range values and the goal value.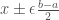 . This will cause the domain to shrink as we get closer to the goal value.
. This will cause the domain to shrink as we get closer to the goal value.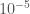 , in about 0.005 seconds.
, in about 0.005 seconds.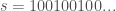 has a gap of two between each of the ‘1’s, and the algorithm can identify this type of structure in polynomial time. You can then use basic modular arithmetic to predict entries beyond the observed dataset, assuming the patterns hold.
has a gap of two between each of the ‘1’s, and the algorithm can identify this type of structure in polynomial time. You can then use basic modular arithmetic to predict entries beyond the observed dataset, assuming the patterns hold.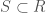 , and assume that
, and assume that  is countable. That is,
is countable. That is,  , maps to only a subset of
, maps to only a subset of 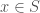 , there is no program that calculates
, there is no program that calculates  be some UTM, and assume that a program
be some UTM, and assume that a program  causes
causes  , that is superior to a UTM. It must be the case that the output
, that is superior to a UTM. It must be the case that the output  , is some representation of the machine
, is some representation of the machine 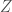 is a complete and accurate representation of the machine
is a complete and accurate representation of the machine 
 frames, then this process will calculate the true average velocity for each frame, expressed as an
frames, then this process will calculate the true average velocity for each frame, expressed as an  matrix, and compare that to the approximated average velocity for each frame, also expressed as an
matrix, and compare that to the approximated average velocity for each frame, also expressed as an 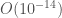 .
.

 be the minimum element,
be the minimum element,  be the maximum element, and let
be the maximum element, and let  , and let
, and let  . However, if the dataset consists of
. However, if the dataset consists of  , and is therefore, independent of the number of vectors in the dataset.
, and is therefore, independent of the number of vectors in the dataset.