I did some work while I was in Stockholm on distributions over countable sets, but stopped in the interest of finishing up what seemed to be, at the time, more important work in physics and A.I. But yesterday, I realized that you can construct a simple model of probability on countable sets using the work that I had abandoned.
Uniform Distributions on Countable Sets
The primary offender for probabilities on countable sets is the uniform distribution. This is because it is impossible to select a real number probability for a uniform distribution on a countable set, since there is no real number r that satisfies,

So instead, my proposal is to drop the requirement that the sum over the probabilities equals 1, and instead to require only that the product of (x) the number of trials and (y) the pseudo-probability of the signal equals (z) the frequency of the signal in question.
So, if each element of a countable set of signals appears exactly once in a countably infinite number of observations, then our pseudo-probability p must satisfy:
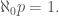
Obviously, 
There’s an additional wrinkle, which is that for countable sets, there are an infinite number of “uniform distributions”. For example, each element of a countable set could appear exactly twice over a countable number of observations, or three times, etc.
Using the natural numbers as our underlying set of signals, we could observe the uniform distributions,

or,

In both cases, each signal appears an equal number of times over a countable number of observations.
So as a general matter, we can instead simply require that,

where 
So our pseudo-probability is a number, that is not a real number, that when multiplied by the number of observations, which is assumed to be 
This definition implies some clean, intuitive arithmetic over these numbers. For example, if signals 

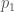


There is, however, a special case where each signal appears a countable number of times. That is, it is possible to have an infinite sequence of observations in which each signal appears a countable number of times.
For example, there are an infinite number of primes, and every prime number can be exponentiated a countably infinite number of times, producing a unique, countably infinite set associated with each prime number.
So let’s assume the primes are our underlying set, and our observations are generated by reading the set of integers in increasing order. If we spot a prime, or a power of a prime, we list the prime number itself as an observation. Otherwise, we write nothing. So if we see 2, we write 2; if we see 9, we write a 3; if we see 16, we write 2; if we see 10, we write nothing.
Reading the first 6 numbers, we would write,

Though we read 6 numbers, we made only 5 observations, since 6 is not prime or a power of a prime.
Reading the number line from left to right in this manner will cause us to list each prime number an infinite of number of times, and because there are an infinite number of primes, we will generate a set of observations that contains a countably infinite number of signals, each of which appears a countably infinite number of times.
Returning to Equation (1) above, we would have in this case,

Any real number would satisfy this equation, but not only is it not intuitive to use a real number in this case, it also implies that there’s more than one solution to the equation, which is pushing the boundaries a bit far, even for a pseudo-probability concept. As a result, my proposition is to use the number,

Note that 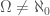

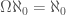
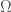
Developing an Intuition for Probabilities on Countable Sets
Intuitively, this makes sense, since if you know that something occurs an infinite number of times in an infinite sequence of observations, the number that describes your expectations for each observation you make in that case should not be a real number probability, since, as shown above, this implies that each real number is just as good as any other real number.
At the same time, the number shouldn’t be an infinitesimal, since the portion of observations in which the signal occurs does not have the same relationship to the total number of observations that an infinitesimal does. That is, if a signal occurs once in a countably infinite sequence, intuitively, if that signal has a well-defined probability, then it should be an infinitesimal, since our expectation is that the event is extraordinarily unlikely to be the current observation, but not truly impossible, since it is actually certain to eventually occur. In contrast, if a signal occurs a countably infinite number of times within a countably infinite sequence of observations, then intuitively, we would not expect the pseudo-probability of that event to be an infinitesimal, since the event could happen often.
For example, if we consider the probability of observing an even number when reading a permutation of the natural numbers, it would be unreasonable to say that the probability is infinitesimal, since there are by definition an infinite number of even numbers in the set that we will eventually observe. At the same time, it’s not quite right to say that the probability is 
And unlike with a finite set of observations, there is no limiting argument that justifies our intuition that the probability of observing an even number increases with the number of observations. It’s simply not true, since for any given sequence of odd numbers, you can construct a permutation on the natural numbers that contains an even longer sequence of odd numbers. As a result, there are also what I would call philosophical reasons to believe that this probability should not be a real number, or an infinitesimal.
And
All of this suggests a different notion of expectation when reading an infinite string, versus reading a finite string. If you’re reading an infinite string, its structure is already determined, but unknown to you. In some sense, this might seem overly philosophical, but it changes the mathematics. When observing a source governed by ordinary probabilities, the assumption is that, eventually, the distribution of the observations will converge to some stable probability distribution. Perhaps you know what this distribution is beforehand, and perhaps you don’t. But in either case, your operating assumption is that within finite time, some distribution will become apparent, and roughly stable.
In contrast, when reading an infinite string, the structure of the string is already pre-determined. Moreover, the set of all infinite strings includes strings that have no stable distribution at all, which, therefore, cannot be described by ordinary probabilities. Instead, we can only count the number of instances of each signal within the string, as we have above, and form a different notion of expectation, that is nonetheless useful, but distinct from the notion of expectation used in ordinary probability. Also note that unless we know the distribution of signals within an infinite string ex ante, it would be impossible to have any expectations at all about any observations, other than knowing the set of possible signals (assuming we have that information ex ante).
We can also take the view that infinitesimals are no different than ordinary real numbers. In short, just like the actual number 
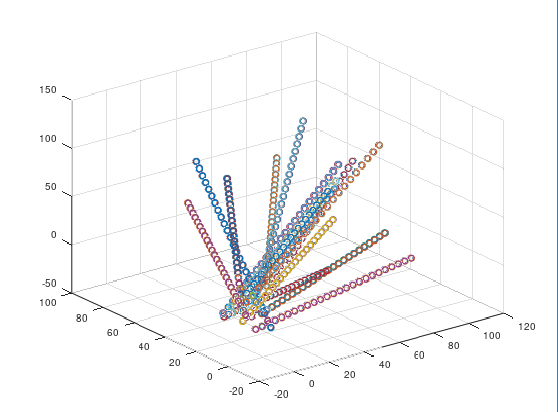
 as a radius. Because this method works so well, it must be the case that this assumption is in fact true for a lot of real world data. Common sense suggests that this is a reasonable assumption, since, for example,
as a radius. Because this method works so well, it must be the case that this assumption is in fact true for a lot of real world data. Common sense suggests that this is a reasonable assumption, since, for example,  and
and  have the same classifier if
have the same classifier if  and
and 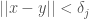 , for some values
, for some values 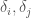 that depend upon the space in question. This would be useful where the space is locally consistent, but only after some initial offset. As a general matter, we could in theory use any computable mathematical operators to construct a function that determines whether two points have the same classifier.
that depend upon the space in question. This would be useful where the space is locally consistent, but only after some initial offset. As a general matter, we could in theory use any computable mathematical operators to construct a function that determines whether two points have the same classifier.