I’ve seen some research online about using complex numbers in automata, and a while back in Stockholm, I noticed that you can form a closed set over , by simply multiplying any element of the set by any other, and I haven’t seen this used in automata anywhere else. I’ve obviously been a bit busy working on my A.I. software, Black Tree AutoML, but today I took some time out to put together a simple script that generates automata using this set. There’s only one rule, which is to simply take the product over a subset of , which means the behavior is determined entirely by the initial conditions, and the boundary conditions (i.e., the top and bottom and therefore immutable rows). This produces possible outcomes using uniform values for the initial conditions and the boundary conditions (i.e., the initial conditions and boundary conditions are independent of each other, and are each elements of ). Here are the 16 possible outputs, with 250 rows, and 500 iterations (i.e., columns):
Each output, again, has two variables: the initial row, set to a single value taken from , and the value of the top and bottom row, also taken from , which produces possible outputs. Unfortunately, the file names, which had the initial and boundary values in them, got screwed up during upload, and I’m not redoing it, but you can produce all of these using the code attached below, as there’s only 16 of them. You’ll note CA (1,1) and CA (-1,-1) are opposites (i.e., initial row = 1, boundary rows = 1; and initial row = -1, boundary rows = -1), in that one is totally white, and one is totally black. This follows from basic arithmetic, since if all initial cells are 1 (white), then any product among them will be 1. Similarly, if all initial cells are -1 (black), then any three cells will produce a product of -1 (the algorithm takes the product over exactly 3 cells). I also noticed what seem to be other algebraic relationships among them, where cells flip from green to blue, and black to white.
The shapes are simply beautiful, achieved using nothing other than multiplication, but beyond aesthetics, the notion more closely tracks an intuitive model of physics, in that there should be only one rule, that is then applied to some set of conditions, which is exactly what you get using this model. In contrast, typical cellular automata have many rules (e.g., for a three bit rule, there are eight possible combinations, producing possible rules). As a consequence, there’s a lot of interplay between the initial conditions, and the rule, when using typical automata. In contrast, in this model, there’s exactly one rule, and so the behavior is determined entirely by the initial conditions, which is exactly what you would expect in the real world, where I think it’s fair to say, we assume the existence of one, comprehensive rule of physics (see, e.g., Section 1.4 of my paper, A Computational Model of Time-Dilation). I’m not suggesting this set of automata define the fundamental rule of physics. The point is instead, if you want to model physics, using automata, and you’re being intellectually honest, you should probably use something like this, unless of course, you’re just trying to be practical, which is a different goal.
It dawned on me tonight, while working on some code, that there are statements that will compile in a language, but cannot be expressed without running the complier twice, once to generate code, and the second time, to run the generated code. I’ll simply provide a more academic version of the exact problem I had, which was specifying a statement that could be generated using the text processing functions of a language, but cannot be directly expressed in the language itself as a general matter. To make things concrete, consider a set of natural numbers, and assume that is an infinite, and non-computable subset of the natural numbers, which must exist, since the set of all subsets of the natural numbers is uncountable, whereas the set of all programs is of course countable. Now assume you want to generate exactly the following statement:
,
where is the i-th number in the set . Because is a non-computable subset, there is no general equation that will allow you to generate the entries in , and so as a consequence, you cannot generate the statement above, as a general matter, without first generating the first entries of . As a consequence, as a general matter, you must run the compiler twice, in order to generate a statement that is nonetheless accepted in the language of the complier. This might be a known result, but I’ve never heard of it before, and as a general matter, it suggests a useful method of programming, that uses the text processing functions of a language to generate statements that will compile, but would otherwise be impossible to generate. And though it’s not impossible to generate the code in my A.I. software, it turns out, this is exactly how the front-end GUI for Black Tree works, in that the user makes a series of selections, which causes the GUI to generate the relevant code.
This is a sort-based version of the algorithm I discuss in Information, Knowledge, and Uncertainty, that uses the modal class of a cluster to predict the class of its geometric origin. I’m still testing it, but the accuracy seems excellent so far. It’s the exact same technique as the other sort-based algorithms, that uses sorting as a substitute for Nearest Neighbor. I proved that sorting has a deep connection to the Nearest Neighbor method in Sorting, Information, and Recursion, which forms the theoretical basis for these algorithms. The accuracies and runtimes shown below are taken on average, over 100 iterations. The testing percentage is set to 15% for all datasets (i.e., 100 rows produces 85 training rows, and 15 testing rows). Accuracy generally increases as a function of confidence, and there are two measures, one information-based, using the equations I presented in the paper Information, Knowledge, and Uncertainty, and the other size-based, which simply treats the cluster size itself as a measure of confidence (i.e., the measure of confidence is literally given by the cluster size, causing larger clusters to be treated as more reliable than smaller clusters).
Dataset
Raw Accuracy
Max Accuracy (Information-Based Conf.)
Max Accuracy (Size-Based Conf.)
No. Rows
Runtime (Seconds)
UCI Abalone
53.88%
100.0%
80.72%
4177
0.460
UCI Credit
72.12%
100.0%
79.69%
2500
0.081
UCI Ion
98.21%
100.0%
100.0%
351
0.016
UCI Iris
93.66%
100.0%
100.0%
150
0.009
UCI Parkinsons
97.78%
100.0%
100.0%
195
0.006
UCI Spam
80.18%
100.0%
100.0%
4601
0.370
UCI Wine
100%
100.0%
100.0%
178
0.004
Here’s the code, any missing functions can be found in my library on ResearchGate.
This is somewhere in my code library, but here it is again, as I might use it for the Massive Version of Black Tree, which should be ready early to mid-June. All it does is test accuracy as a function delta, rather than run the original supervision step. The idea here is, you produce a single value that generates the highest accuracy, or the desired number of rejections.
This algorithm is a more efficient analog of the algorithm that calculates delta for my Supervised Delta Algorithm. There are two versions, one that trains on the full dataset, and one that trains a compressed dataset, further reducing the runtime by a factor of roughly 1/2. The underlying algorithm is the same for both methods, and there are two command lines attached, one that implements each, both set up as functions for convenience. The accuracies are excellent, except for UCI Abalone for some strange reason. The runtime is about 1 second (full dataset) and .5 seconds (compressed dataset) for every 2,500 rows. The accuracies below are the averages over 100 iterations per dataset, split into 85% training rows, 15% testing rows. As you can see, compression doesn’t really impact accuracy too much, but it is roughly twice as fast, which can make a big difference for the intended product, which is designed for a large number of rows run locally (i.e., on a desktop / laptop).
This is exactly the same technique I posted the other day, that uses sorting to achieve an approximation of the nearest neighbor method. Then, clusters are generated by beginning at a given index in the sorted list, and including rows to the left and right of the index, iterating through increasing boundary indexes, simulating expanding the radius of a sphere (i.e., as you include more rows to the left and right of a given index, you are effectively including all rows within a sphere of increasing radius from the origin / index). The only substantive change in this case, is the use of volume in calculating confidence (the other changes were corrections). Specifically, uncertainty increases as a function of volume, for the simple reason that, if you have a cluster contained within a large volume, and few rows in the cluster, then you have more uncertainty (c.f., a large number of rows contained in a small volume). In my original confidence-based classification algorithm, the spheres are all fixed sizes, so you could argue it didn’t matter in that case (especially since it works). I came up with yet another method, that makes use of a combinatorial measure of uncertainty that I mentioned in Footnote 14 of Information, Knowledge, and Uncertainty, which also should work for variable sized clusters, which I should be done with soon.
This particular algorithm is incredibly fast, classifying 4,500 testing rows, over 25,500 training rows, in about two seconds, with accuracy that often peaks at close to perfect (i.e., accuracy increases as a function of confidence). The chart below shows accuracies and runtimes for this method, on average over 100 iterations. All of the testing percentages are fixed at 15% (i.e., 30,000 rows implies 4,500 Testing Rows and 25,500 Training Rows). The Raw Accuracy is the accuracy of the method on its own, with no confidence filtering, which is almost always terrible. The Max Accuracies are given for both the information-based confidence metric, which diminishes as a function of volume, and the size-based confidence metric, which does not, and simply looks to the number of elements in each cluster (i.e., the more cluster elements, the higher the confidence). Confidence filtering is achieved by simply ignoring all predictions that carry a confidence of less than , which generally causes accuracy to increase as a function of . All of the max accuracies are excellent, except UCI Sonar, which is a dataset that’s given me problems in the past. I plan to address UCI Sonar separately with an analog to my Supervised Delta Algorithm, that will also make use of sorting.
Dataset
Raw Acc.
Max Acc. (Inf.)
Max Acc. (Size)
Runtime (Seconds)
No. Rows
UCI Credit
38.07%
78.30%
100.0%
3.290
30,000
UCI Abalone
17.37%
83.50%
71.30%
0.322
4,177
UCI Spam
40.83%
98.61%
100.0%
0.469
4,601
UCI Ion
53.00%
94.30%
100.0%
0.057
351
UCI Iris
32.50%
100.0%
86.20%
0.024
150
UCI Parkinsons
47.20%
95.60%
100.0%
0.035
195
UCI Wine
37.50%
94.20%
100.0%
0.029
178
UCI Sonar
20.16%
58.11%
34.80%
0.048
208
There’s more to come, with simple variations on this overall method, that just reapplies my core work using a sorted list. Once that’s complete, I’ll write something more formal about these methods.
Here’s the code, you can find the normalization algorithm a few posts below. The Command Line is set up as a function, for convenience (MASSTempFunction), so just change the dataset path in that file, and you’re good to go.
Chaos is a word that gets thrown around a lot, and I know nothing about Chaos Theory, which is at this point probably a serious branch of mathematics, but again, I know nothing about it. However, it dawned on me, that you can think about chaos in terms of information, using Cellular Automata as the intuition. Specifically, consider the initial conditions of a binary automaton, which together form a single vector of binary digits. Then you have the rule, , which takes those initial conditions, and mechanistically generates the rows that follow. Let be a particular set of initial conditions (i.e., a particular binary vector), so that is the result of applying to the initial conditions , for some fixed number of iterations. Now change exactly one bit of , producing , which in turn produces . Now count the number of unequal bits between and , which must be at least one, since we changed exactly one bit of to produce . Let be the number of unequal bits between and , and let be the number of bits changed in , to produce . We can measure how chaotic is in bits, as the ratio,
.
Said in words, is the ratio of the total number of bits that change divided by the number of bits changed in the initial conditions.
This is basically the same as the original algorithm on the topic, though I fixed a few bugs, and provided a command line that makes it easy to generate a confidence / accuracy distribution. The runtime is astonishing, about 2 seconds per 30,000 rows. More to come soon.
Here’s another version of my supervised clustering algorithm that saves a few steps using sorting, but it turns out it doesn’t matter much (it seems to be about twice as fast).
Here’s another version of the same algorithm from the previous post, there are some slight changes, and this one seems to have higher accuracy in general. Again, I’ll post something explaining how they work sometime soon.




















![x = [S_1, S_2, \ldots, S_k];](https://s0.wp.com/latex.php?latex=x+%3D+%5BS_1%2C+S_2%2C+%5Cldots%2C+S_k%5D%3B&bg=ffffff&fg=444444&s=0&c=20201002) ,
, is the i-th number in the set
is the i-th number in the set  entries of
entries of  , which generally causes accuracy to increase as a function of
, which generally causes accuracy to increase as a function of  binary digits. Then you have the rule,
binary digits. Then you have the rule,  , which takes those initial conditions, and mechanistically generates the rows that follow. Let
, which takes those initial conditions, and mechanistically generates the rows that follow. Let  be a particular set of initial conditions (i.e., a particular binary vector), so that
be a particular set of initial conditions (i.e., a particular binary vector), so that  is the result of applying
is the result of applying  iterations. Now change exactly one bit of
iterations. Now change exactly one bit of  , which in turn produces
, which in turn produces  . Now count the number of unequal bits between
. Now count the number of unequal bits between  and
and  , which must be at least one, since we changed exactly one bit of
, which must be at least one, since we changed exactly one bit of  be the number of unequal bits between
be the number of unequal bits between  be the number of bits changed in
be the number of bits changed in 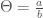 .
.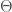 is the ratio of the total number of bits that change divided by the number of bits changed in the initial conditions.
is the ratio of the total number of bits that change divided by the number of bits changed in the initial conditions.