In a previous post below entitled, “Image Recognition with No Prior Information”, I introduced an algorithm that can identify structure in random images with no prior information by making use of assumptions rooted in information theory. As part of that algorithm, I showed how we can use the Shannon entropy of a matrix to create meaningful, objective categorizations ex ante, without any prior information about the data we’re categorizing. In this post, I’ll present a generalized algorithm that can take in an arbitrary data set, and quickly construct meaningful, intuitively correct partitions of the data set, again with no prior information.
Though I am still conducting research on the run-time of the algorithm, the algorithm generally takes only a few seconds to run on an ordinary commercial laptop, and I believe the worst case complexity of the algorithm to be  , where n is the number of data points in the data set.
, where n is the number of data points in the data set.
The Distribution of Information
Consider the vector of integers x = [1 2 3 5 10 11 15 21]. In order to store, convey, or operate on x, we’d have to represent x in some form, and as a result, by its nature, x has some intrinsic information content. In this case, x consists of a series of 8 integers, all less than 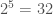 , so we could, for example, represent the entire vector as a series of 8, 5-bit binary numbers, using a total of 40 bits. This would be a reasonable measure of the amount of information required to store or communicate x. But for purposes of this algorithm, we’re not really interested in how much information is required to store or communicate a data set. Instead, we’re actually more interested in the information content of certain partitions of the data set.
, so we could, for example, represent the entire vector as a series of 8, 5-bit binary numbers, using a total of 40 bits. This would be a reasonable measure of the amount of information required to store or communicate x. But for purposes of this algorithm, we’re not really interested in how much information is required to store or communicate a data set. Instead, we’re actually more interested in the information content of certain partitions of the data set.
Specifically, we begin by partitioning x into equal intervals of Δ = (21-1) / N, where N is some integer. That is, we take the max and min elements, take their difference, and divide by some integer N, which will result in some rational number that we’ll use as an interval with which we’ll partition x. If we let N = 2, then Δ = 10, and our partition is given by {1 2 3 5 10 11} {15 21}. That is, we begin with the minimum element of the set, add Δ, and all elements less than or equal to that minimum + Δ are included in the first subset. In this case, this would group all elements from 1 to 1 + Δ = 11. The next subset is in this case generated by taking all numbers greater than 11, up to and including 1 + 2Δ = 21. If instead we let N = 3, then Δ = 6 + ⅔, and our partition is in this case given by {1 2 3 5} {10 11} {15 21}.
As expected, by increasing N, we decrease Δ, thereby generating a partition that consists of a larger number of smaller subsets. As a result, the information content of our partition changes as a function of N, and eventually, our partition will consist entirely of single element sets that contain an equal amount of information (and possibly, some empty subsets). Somewhere along the way from N = 1 to that maximum, we’ll reach a point where the subsets contain maximally different amounts of information, which we treat as an objective point of interest, since it is an a priori partition that generates maximally different subsets, at least with respect to their information content.
First, we’ll need to define our measure of information content. For this purpose, we assume that the information content of a subset is given by the Shannon information,
 ,
,
where p is the probability of the subset. In this case, the partition is a static artifact, and as a result, the subsets don’t have real probabilities. Nonetheless, each partition is by definition comprised of some number of m elements, where m is some portion of the total number of elements M. For example, in this case, M = 8, and for Δ = 6 + ⅔, the first subset of the partition consists of m = 4 elements. As a result, we could assume that p = m/M = ½, producing an information content of log(2) = 1 bit.
As noted above, as we iterate through values of N, the information contents of the subsets will change. For any fixed value of N, we can measure the standard deviation of the information contents of the subsets generated by the partition. There will be some value of N for which this standard deviation is maximized. This is the value of N that will generate maximally different subsets of x that are all nonetheless bounded by the same interval Δ.
This is not, however, where the algorithm ends. Instead, it is just a pre-processing step we’ll use to measure how symmetrical the data is. Specifically, if the data is highly asymmetrical, then a low value of N will result in a partition that consists of subsets with different numbers of elements, and therefore, different measures of information content. In contrast, if the data is highly symmetrical, then it will require several subdivisions until the data is broken into unequally sized subsets.
For example, consider the set {1, 2, 3, 4, 15}. If N = 2, then Δ = 7, and immediately, the set set is broken into subsets of {1, 2, 3, 4} and {15}, which are of significantly different sizes when compared to the size of the original set. In contrast, given the set {1, 2, 3, 4, 5}, if N = 2, then Δ = 2, resulting in subsets of {1, 2, 3} {4, 5}. It turns out that the standard deviation is in this case maximized when N = 3, resulting in a partition given by {1, 2} {3} {4, 5}. We can then express the standard deviation of the partition as an Octave vector:
std( [ log(5/2) log(5) log(5/2) ] ) = 0.57735.
As a result, we can use N as a measure of symmetry, which will in turn inform how we ultimately group elements together into categories. The attached partition_vec script finds the optimum value of N.
Symmetry, Dispersion, and Expected Category Sizes
To begin, recall that N can be used as a measure of the symmetry of a data set. Specifically, returning to our example x = [1 2 3 5 10 11 15 21] above, it turns out that N = 2, producing a maximum standard deviation of 1.1207 bits. This means that it requires very little subdivision to cause x to be partitioned into equally bounded subsets that contain maximally different amounts of information. This suggests that there’s a decent chance that we can meaningfully partition x into categories that are “big” relative to its total size. Superficially, this seems reasonable, since, for example, {1 2 3 5} {10 11 15} {21} would certainly be a reasonable partition.
As a general matter, we assume that a high value of N creates an ex ante expectation of small categories, and that a low value of N creates an ex ante expectation of large categories. As a result, a high value of N should correspond to a small initial guess as to how different two elements need to be in order to be categorized separately, and a low value of N should correspond to a large initial guess for this value.
It turns out that the following equation, which I developed in the context of recognizing structure in images, works quite well:
 ,
,
where divisor is the number by which we’ll divide the standard deviation of our data set, generating our initial minimum “guess” as to what constitutes a sufficient difference between elements in order to cause them to be categorized separately. That is, our initial sufficient difference will be proportional to s / divisor.
“Symm” is, as the name suggests, yet another a measure of symmetry, and a measure of dispersion about the median of a data set. Symm also forms the basis of a very simple measure of correlation that I’ll discuss in a follow up post. Specifically, symm is given by the square root of the average of the sum of the squares of the differences between the maximum and minimum elements of a set, the second largest and second smallest element of a set, and so on.
For example, in the case of the vector x, symm is given by,
![[\frac{1}{8} ( (21 - 1)^2 + (15 - 2)^2 + (11 -3)^2 + (10 - 5)^2 + (10 - 5)^2 + (11 -3)^2 + (15 - 2)^2 + (21 - 1)^2 )]^{\frac{1}{2}},](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7B1%7D%7B8%7D+%28+%2821+-+1%29%5E2+%2B+%2815+-+2%29%5E2+%2B+%2811+-3%29%5E2+%2B+%2810+-+5%29%5E2+%2B+%2810+-+5%29%5E2+%2B+%2811+-3%29%5E2+%2B+%2815+-+2%29%5E2+%2B+%2821+-+1%29%5E2+%29%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%2C&bg=ffffff&fg=444444&s=0&c=20201002)
which is 12.826.
As we increase the distance between the elements from the median of a data set, we increase symm. As we decrease this distance, we decrease symm. For example, symm([ 2 3 4 5 6 ]) is greater than symm([ 3 3.5 4 4.5 5 ]). Also note that a data set that is “tightly packed” on one side of its median and diffuse on the other will have a lower value of symm than another data set that is diffuse on both sides of its median. For example, symm([ 1 2 3 4 4.1 4.2 4.3 ]) is less than symm([ 1 2 3 4 5 6 7 ]).
For purposes of our algorithm, symm is yet another a measure of how big we should expect our categories to be ex ante. A large value of symm implies a data set that is diffuse about its median, suggesting bigger categories, whereas a small value of symm implies a data set that is tightly packed about its median, suggesting smaller categories. For purposes of calculating divisor above, we first convert the vector in question into a probability distribution by dividing by the sum over all elements of the vector. So in the case of x, we first calculate,
x’ = [0.014706 0.029412 0.044118 0.073529 0.147059 0.161765 0.220588 0.308824].
Then, we calculate symm(x’) = 0.18861. Putting it all together, this implies divisor = 0.30797.
Determining Sufficient Difference
One of the great things about this approach is that it allows us to define an objective, a priori measure of how different two elements need to be in order to be categorized separately. Specifically, we’ll make use of a technique I described in a previous post below that iterates through different minimum sufficient differences, until we reach a point where the structure of the resultant partition “cracks”, causing the algorithm to terminate, ultimately producing what is generally a high-quality partition of the data set. The basic underlying assumption is that the Shannon entropy of a mathematical object can be used as a measure of the object’s structural complexity. The point at which the Shannon entropy changes the most over some interval is, therefore, an objective local maximum where a significant change in structure occurs. I’ve noticed that this point is, across a wide variety of objects, including images and probabilities, where the intrinsic structure of an object comes into focus.
First, let maxiterations be the maximum number of times we’ll allow the main loop of the algorithm to iterate. We’ll want our final guess as to the minimum sufficient difference between categories to be s, the standard deviation of the data set. At the same time, we’ll want our initial guess to be proportional to s / divisor. As a result, we use a counter that begins at 0, and iterates up to divisor, in increments of,
 ,
,
This allows us to set the minimum sufficient difference between categories to,
 ,
,
which will ultimately cause delta to begin at 0, and iterate up to s, as counter iterates from 0 to divisor, increasing by increment upon each iteration.
After calculating an initial value for delta, the main loop of the algorithm begins by selecting an initial “anchor” value from the data set, which is in this case simply the first element of the data set. This anchor will be the first element of the first category of our partition. Because we are assuming that we know nothing about the data, we can’t say ex ante which item from the data set should be selected as the initial element. In the context of image recognition, we had a bit more information about the data, since we knew that the data represented an image, and therefore, had a good reason to impose additional criteria on our selection of the initial element. In this case, we are assuming that we have no idea what the data set represents, and as a result, we simply iterate through the data set in the order in which it is presented to us. This means that the first element of the first category of our partition is simply the first element of the data set.
We then iterate through the data set, again in the order in which it is presented, adding elements to this first category, provided the element under consideration is within delta of the anchor element. Once we complete an iteration through the data set, we select the anchor for the second category, which will in this case be the first available element of the data set that was not included in our first category. This process continues until all elements of the data set have been included in a category, at which point the algorithm measures the entropy of the partition, which is simply the weighted average information content of each category. That is, the entropy of a partition is,
 .
.
We then store H, increment delta, and repeat this entire process for the new value of delta, which will produce another partition, and therefore, another measure of entropy. Let H_1 and H_2 represent the entropies of the partitions generated by delta_1 and delta_2, respectively. The algorithm will calculate 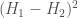 , and compare it to the maximum change in entropy observed over all iterations, which is initially set to 0. That is, as we increment delta, we measure the rate of change in the entropy of the partition as a function of delta, and store the value of delta for which this rate of change is maximized.
, and compare it to the maximum change in entropy observed over all iterations, which is initially set to 0. That is, as we increment delta, we measure the rate of change in the entropy of the partition as a function of delta, and store the value of delta for which this rate of change is maximized.
As noted above, it turns out that, as a general matter, this is a point at which the inherent structure of a mathematical object comes into focus. This doesn’t imply that this method produces the “correct” partition of a data set, or an image, but rather, that it is expected to produce reasonable partitions ex ante based upon our analysis and assumptions above.
Minimum Required Structure
We can’t say in advance exactly how this algorithm will behave, and as a result, I’ve also included a test condition in the main loop of the algorithm that ensures that the resultant partition has a certain minimum amount of structure. That is, in addition to testing for the maximum change in entropy, the algorithm also ensures that the resultant partition has a certain minimum amount of structure, as measured using the entropy of the partition.
In particular, the minimum entropy required is given by,
 ,
,
where symm is the same measure of symmetry discussed above. This minimum is enforced by simply having the loop terminate the moment the entropy of the partition tests below the minimum required entropy.
Note that as the number of items in our data set increases, the maximum possible entropy of the partition, given by log(numitems), increases as well. Further, as our categories increase in size, and decrease in number, the entropy of the resultant partition will decrease. If symm is low (i.e., close to 0), then we have good reason to expect a partition that contains a large number of narrow categories, meaning that we shouldn’t allow the algorithm to generate a low entropy partition. If symm is high, then we can be more comfortable allowing the algorithm to run a bit longer, producing a lower entropy partition. See, “Image Recognition with No Prior Information” on my researchgate page for more on the theory underlying this algorithm, symm, and the Shannon entropy generally.
Applying the Algorithm to Data
Let’s consider the data sets generated by the following code:
for i = 1 : 25
data(i) = base + rand()*spread;
endfor
for i = 26 : 50
data(i) = base + adjustment + rand()*spread;
endfor
This is of course just random data, but to give the data some intuitive appeal, we could assume that base = 4, adjustment = 3, spread = .1, and interpret the resulting data as heights measured in two populations of people: one population that is significantly shorter than average (i.e., around 4 feet tall), and another population that is significantly taller than average (i.e., around 7 feet tall). Note that in Octave, rand() produces a random number from 0 to 1. This is implemented by the attached generate_random_data script.
Each time we run this code, we’ll generate a data set of what we’re interpreting as heights, that we know to be comprised of two sets of numbers: one set clustered around 4, and the other set clustered around 7. If we run the categorization algorithm on the data (which I’ve attached as optimize_linear_categories), we’ll find that the average number of categories generated is around 2.7. As a result, the algorithm does a good job at distinguishing between the two sets of numbers that we know to be present.
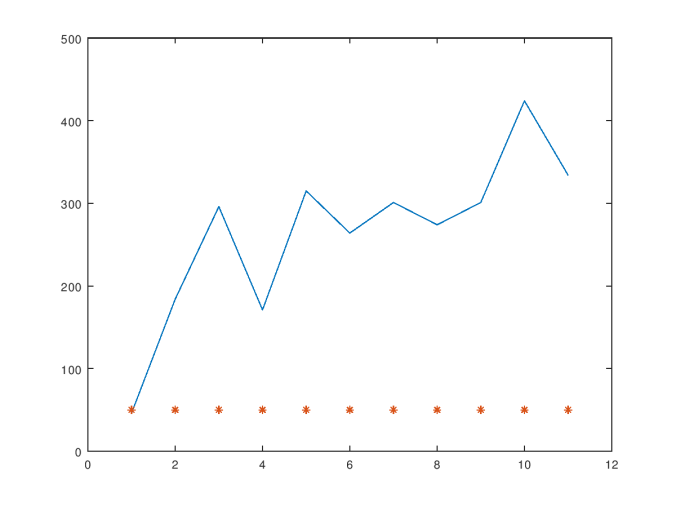
Note that as we decrease the value of adjustment, we decrease the difference between the sets of numbers generated by the two loops in the code above. As a result, decreasing the value of adjustment blurs the line between the two categories of numbers. This is reflected in the results produced by the algorithm, as shown in the attached graph, in which the number of categories decreases exponentially as the value of adjustment goes from 0 to 3.

Similarly, as we increase spread, we increase the intersection between the two sets of numbers, thereby again decreasing the distinction between the two sets of numbers. However, the number of categories appears to grow linearly in this case as a function of spread over the interval .1 to .7, with adjustment fixed at 3.

As a general matter, these results demonstrate that the algorithm behaves in an intuitive manner, generating a small number of wide categories when appropriate, and a large number of narrow categories when appropriate.
Generalizing this algorithm to the n-dimensional case should be straightforward, and I’ll follow up with those scripts sometime over the next few days. Specifically, we can simply substitute the arithmetic difference between two data points with the norm of the difference between two n-dimensional vectors. Of course, some spaces, such as an RGB color space, might require non-Euclidean measures of distance. Nonetheless, the point remains, that the concepts presented above are general, and should not, as a general matter, depend upon the dimension of the data set.
The relevant Octave / Matlab scripts are available here:
generate_linear_categories
generate_random_data
left_right_delta
optimize_linear_categories
partition_vec
spec_log
test_entropy_vec
vector_entropy


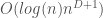 , where D is the dimension of the dataset, making this algorithm exceptionally fast for what it is, which is a data categorization algorithm.
, where D is the dimension of the dataset, making this algorithm exceptionally fast for what it is, which is a data categorization algorithm.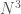 subcubes, and N is necessarily less than or equal to n, it follows that the number of subcubes cannot exceed
subcubes, and N is necessarily less than or equal to n, it follows that the number of subcubes cannot exceed  . As a result, we’ll have to do at most
. As a result, we’ll have to do at most 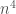 comparisons each time we call test_entropy.
comparisons each time we call test_entropy. ,
,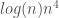 .
.






















 denote the computational complexity of the string
denote the computational complexity of the string  , and let
, and let 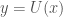 denote the output of a UTM when given
denote the output of a UTM when given  , by definition,
, by definition,  . Put informally,
. Put informally,  is the length, measured in bits, of the shortest program that generates
is the length, measured in bits, of the shortest program that generates  . That is, we can generate
. That is, we can generate  that does not depend upon
that does not depend upon  ,
, .
.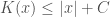 . That is, we can just feed the input x to a UTM that simply copies its input, so a string is never more complex than its own length plus a constant. As a result, assuming
. That is, we can just feed the input x to a UTM that simply copies its input, so a string is never more complex than its own length plus a constant. As a result, assuming  , than we are to generate
, than we are to generate 