If we know truly nothing at all about a data set, then the fact that the data is presented to us as a collection of vectors does not necessarily imply that there is any connection between the underlying dimensions of the vectors. That is, it could just be a coincidence that has caused these otherwise independent dimensions of data to be combined into vector form. This suggests that whether we create categories based upon the vectors as a whole, or the individual dimensions of the vectors, will depend upon our ex ante assumptions about the data.
Even in the case where the components of the vectors are not statistically correlated, it could still nonetheless be rational to treat the components as part of a whole. This would be the case whenever a combination of underlying characteristics affects the whole. Color is a good example of this. As a general matter, we’ll probably want to categorize colors as a whole (i.e., a single RGB vector), but the individual components of a data set of colors might not necessarily be correlated with each other. That is, we could be given a data set of colors where the red, blue, and green luminosity levels are all statistically independent of each other. Nonetheless, the combinations of color luminosities determine the perceived colors, and therefore, we can rationally construct categories using entire vectors, and not just the components of the vectors, despite the fact that the components of the vectors might be statistically independent of each other. In this case, this is driven by a perceptual phenomenon, since it just happens to be the case that the brain combines different exogenous wavelengths of light into a single perceived color.
This example highlights the distinction between (1) statistical correlation between the components of a vector, and (2) the co-relevance of the components of a vector in their contribution to some whole that is distinct from its underlying components.
Similar ideas apply to music, where a chord produces something that is distinct from its individual components. That is, when a single note is played, there is no harmony, since by definition there is only one note. This is in some sense a point of semantics, but it can also be expressed mathematically. That is, when a single note is played, there is no relationship to be considered between any two notes, since there is, of course, only one note. When two notes are played, however, not only are there two auditory signals being generated, but there is a third distinct artifact of this arrangement, which is the relationship between the two notes. As we add notes to the chord, the number of relationships between the notes increases.
We can count these relationships using simple combinatorics. For example, 3 notes played simultaneously creates 7 distinct perceptual artifacts. Specifically, there are the 3 individual notes; the 3 combinations of any two notes; and the 1 combination of all 3 notes. An untrained musician might not be conscious of these relationships, whereas a trained musician will be. But in either case, in a manner more or less analogous to how a blue and a red source produce magenta, which is a non-spectral color, two or more notes generate higher order perceptual experiences that are fundamentally different than those generated by their individual components. That is, harmony is a perceptual experience that must be distinct from the signals generated by its underlying components, since certain combinations of notes are known to be harmonious, whereas others are not, and instead produce dissonance (i.e., combinations of notes that “clash”).
Unlike visual art, which exists in a Euclidean space, music extends through time, in a fairly rigorous manner, with definite mathematical relationships between the notes played at a given moment, and between the notes played over time. Moreover, these relationships change in a non-linear manner as a function of the underlying variables. For example, a “major third” is arguably the most pleasant sound in music, and is generally associated with an expression of joy (think of the melody from Beethoven’s, “Ode to Joy”). One half-step down (which is the minimum decrement in the 12-tone scale), and we find the minor third, which, while harmonious, is generally associated with an expression of sadness (think of the opening to Beethoven’s, “Moonlight Sonata”). One whole-step down from a major third, we find a harmonically neutral combination between the root of a chord and the second note in the related scale. That is, adding this note to a chord doesn’t really change the character of the chord, but adds a bit of richness to it. In contrast, one whole step up from a major third, and we find a tritone, which is a dissonance so visceral, it’s generally associated with evil in cheesy horror movies, producing a demented sound (have a listen to the opening of “Totentanz”, by Franz Liszt).
In short, though there are undoubtedly patterns in music, the underlying space is extremely complex, and varies in an almost chaotic manner (at least over small intervals) as a function of its fundamental components.
This suggests that generating high-quality, complex music is probably a much harder problem than generating high-quality visual art. With all due respect to visual artists, the fact is that you can add statistical noise to the positions of pixels in a Picasso, and it will still look similar to the original piece. Similarly, you can add statistical noise to its colors, and nonetheless produce something that looks close to the original piece. As a result, it suggests that you can “approximate” visual art using statistical techniques. This is a consequence of the space in which visual art exists, which is a Euclidean physical space, and a roughly logarithmic color space. In contrast, if you “blur” Mahler’s 5th Symphony, changing the notes slightly, you’re going to produce a total disaster. This is a consequence of the underlying space in music, which is arguably chaotic over small intervals, though it certainly has patterns over large intervals.
Upon reflection, it is, therefore, actually remarkable that human beings can take something as complex as a symphony, which will have an enormous number of relationships to consider, that change randomly as a function of their underlying variables, and reduce it to a perceptual experience that is either harmonious or not. The ability to create something so complex that is nonetheless structured, and perceived in a unitary manner by others, borders on the astonishing.
It suggests that the minds of people like Mozart, Beethoven, and Brahms, could provide insights into how some human beings somehow operate as net contributors of structured information, despite the fact that it is mathematically impossible for a classical computer to generate “new information”, since the Kolmogorov complexity of the output of a Turning Machine is always less than or equal to the complexity of its input. That is, a Turing Machine can alter, and destroy information, but it cannot create new information that did not exist beforehand.
This can be easily proven as follows:
Let 

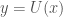





We could, therefore, take the view that meaningful non-determinism is the best evidence for computation beyond what is possible by a UTM.
That is, if a source generates outputs, the complexities of which consistently exceed the aggregate complexities of any apparent inputs, then that source simply cannot be computable, since, as we just proved above, computable processes cannot generate complexity. If it is also the case that this source generates outputs that have structure, then we cannot say that this source is simply producing random outputs. Therefore, any such source would be a net contributor of structured information, which means that the source would be a non-random, non-computable source.
I am clearly suggesting the possibility that at least some human beings are capable of producing artifacts, the complexities of which exceed the aggregate complexities of any obvious sources of information. In short, human creativity might be the best evidence for non-random, non-computable processes of nature, which would in turn, imply that at least some human beings are fundamentally different from all known machines. This view suggests that, similarly, our greatest mathematicians weren’t operating as theorem provers, beginning with assumptions and mechanistically deducing conclusions, but were perhaps arriving at conclusions that did not follow from any obvious available sources of information, with minds that made use of processes of nature that we do not yet fully understand. This is probably why these people are referred to as geniuses. That is, the artifacts produced by people like Newton, Gauss, and Beethoven are astonishing precisely because they don’t follow from any obvious set of assumptions, but are instead only apparent after they’ve already been articulated.
But in addition to the admittedly anecdotal narrative above, there is also a measure of probability developed by Ray Solomonoff that provides a more convincing theoretical justification for the view that human creativity probably isn’t the product of a computable process. Specifically, Solomonoff showed that if we provide random inputs to a UTM (e.g., a binary coin toss), then the probability of that UTM generating a given output string

where 
We can certainly iteratively generate all binary inputs to a UTM, and it is almost certainly the case that, for example, no one has stumbled upon the correct input to a UTM that will generate Mahler’s 5th symphony. So, if we want to argue that the creative process is nonetheless the product of a computable process, it follows that the computable process, in this case, Mahler’s creative process, is the product happenstance, where a series of random inputs serendipitously found their way to Gustav Mahler, ultimately causing his internal mental process to generate a masterpiece.
In addition to sounding ridiculous when stated in these terms, it turns out that Solomonoff’s equation above also casts serious doubt on this as a credible possibility. Specifically, because we’ve presumably yet to find the correct input to a UTM that will generate Mahler’s 5th symphony, this input string is presumably fairly large. This implies that the probability that an encoded version of Mahler’s 5th will be generated by a UTM given random inputs is extremely low. As a result, we’re left with the conclusion that large, high-complexity artifacts that nonetheless have structure are probably not the product of a random input being fed to a UTM. Moreover, such artifacts are even less likely to be the product of pure chance, since 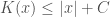

As a result, Solomonoff’s equation expresses something we all know to be true in mathematical terms: I can toss coins for a billion years, and I’ll still never produce something like Mahler’s 5th. In the jargon of computer theory, Mahler’s 5th Symphony might be the best evidence that the Church-Turing Thesis is false.
This view is even more alarming when you consider the algorithmic probability of generating a DNA molecule…
