The market tanked about 4.0% this Tuesday, and I naturally searched for causes, like everyone else does, because the event is unlikely, in the sense that most trading days don’t produce such large moves in either direction. But I also acknowledge that it could have been a random outcome, in the most literal sense, that the motion of the S&P 500 was on that day determined by a repeated toll of a random variable, and that’s not something you can simply rule out. Nonetheless, the intuition is there, that low probability events are connected to causation, in the sense that they shouldn’t happen without an intervening cause, simply because they’re so unlikely. This view is however incomplete, and it’s something I’ve commented on in the past, specifically, that what you’re looking to is a property that has a low probability, rather than the event itself. In the case of an asset price, we’d be looking at paths that go basically straight up or straight down, which are few in number, compared to the rest of the paths that generally meander in no particular direction. This can be formalized using one of the first original datasets I put together, that generates random paths that resemble asset prices. In this dataset, there will be exactly two extremal paths that go maximally up and maximally down, and for that reason, those two paths are special, and from a simple counting perspective, there will be exactly two of them out of many.
To continue this intuition with another example, consider sequences generated by repeated coin tosses, e.g., HTH, being the product of flipping heads, then tails, then heads. The probability of any sequence is simply 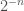 , where
, where  is the length of the string, but this fails to capture the surprisal generated by, e.g., producing a sequence that is billions of entries long, and comprised of only heads. If this really happened, you’d be astonished, but it nonetheless is no more or less likely than any other sequence of equal length. As a consequence, measuring surprisal using the Shannon Entropy produces the same result, treating all outcomes equally, because all sequences have equal probabilities. The intuition at work here can instead be formalized using the Kolmogorov Complexity. Specifically, consider all strings of a given length, now calculate the Kolmogorov Complexity of each such string, producing a distribution of complexities. Now your surprisal can be described objectively, since the probability of generating, e.g., an alternating sequence of (HTHTHTH …) of any appreciable length, is also low, just like generating a uniform sequence of (HHHHHHH …) of any appreciable length. The point here, is that what produces surprisal in at least some cases is the Kolmogorov Complexity of an observation, in that large highly structured objects have a low probability over the distribution of complexities, since most strings are Kolmogorov-Random (i.e., have high complexities).
is the length of the string, but this fails to capture the surprisal generated by, e.g., producing a sequence that is billions of entries long, and comprised of only heads. If this really happened, you’d be astonished, but it nonetheless is no more or less likely than any other sequence of equal length. As a consequence, measuring surprisal using the Shannon Entropy produces the same result, treating all outcomes equally, because all sequences have equal probabilities. The intuition at work here can instead be formalized using the Kolmogorov Complexity. Specifically, consider all strings of a given length, now calculate the Kolmogorov Complexity of each such string, producing a distribution of complexities. Now your surprisal can be described objectively, since the probability of generating, e.g., an alternating sequence of (HTHTHTH …) of any appreciable length, is also low, just like generating a uniform sequence of (HHHHHHH …) of any appreciable length. The point here, is that what produces surprisal in at least some cases is the Kolmogorov Complexity of an observation, in that large highly structured objects have a low probability over the distribution of complexities, since most strings are Kolmogorov-Random (i.e., have high complexities).
There is moreover, a plain connection between complexity and sentience, because anecdotally, that is generally how large and highly structured objects are produced, i.e., through deliberate action, though this is at times erroneous, since e.g., gravity produces simply gigantic, and highly structured systems, like our Solar System, and gravity is not in any scientific sense, sentient, and instead it has a simple mechanical behavior. However, there is nonetheless a useful, intuitive connection between the Kolmogorov Complexity and sentience, in that as you increase Kolmogorov Complexity from the mundane (e.g., (HHHHH …) or (HTHTHT …)) to the elaborate, but nonetheless patterned, it becomes intuitively more difficult to dismiss the possibility that the sequence was produced by a sentient being, as opposed to being randomly generated. Just imagine e.g., someone telling you that a randomly generated set of pixels produced a Picasso – you would refuse to believe it, justifiably, because highly structured macroscopic objects just don’t get generated that way.
And I’ve said many times, it is simply not credible in this view that life is the product of a random sequence, because that assumption produces probabilities so low, that there’s simply not enough time in the Universe to generate systems as complex as living systems. At the same time, an intervening sentient creator, only produces the same problem, because that sentience would in turn require another sentient creator, and so on. The article I linked to goes through some admittedly imprecise math, that is nonetheless impossible to argue against, but to get the intuition, there are 3 billion base pairs in human DNA. Each base pair is comprised of two selections from four possible bases, adenine (A), cytosine (C), guanine (G) [GWA-NeeN] or thymine (T). Ignoring restrictions, basic combinatorics says there are 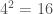 possible base pairs. Because there are 3 billion base pairs in human DNA, the total number of possible genetic sequences is
possible base pairs. Because there are 3 billion base pairs in human DNA, the total number of possible genetic sequences is  , where is 3 billion. This is a number so large, it cannot be calculated on most machines (e.g., Google cannot calculate it), and for context, the number of seconds since the Big Bang is about
, where is 3 billion. This is a number so large, it cannot be calculated on most machines (e.g., Google cannot calculate it), and for context, the number of seconds since the Big Bang is about  (i.e. a number with 18 digits), whereas the number of possible DNA sequences has at least 3 billion digits. Note that while this is plainly rough arithmetic, the number of possible base pairs does not have to be 16 to produce this problem, since if the number of possible base pairs is anything greater than 1 (and it obviously is greater than 1), then you still have a number with roughly billions of digits –
(i.e. a number with 18 digits), whereas the number of possible DNA sequences has at least 3 billion digits. Note that while this is plainly rough arithmetic, the number of possible base pairs does not have to be 16 to produce this problem, since if the number of possible base pairs is anything greater than 1 (and it obviously is greater than 1), then you still have a number with roughly billions of digits –
This is a joke of an idea, and instead, I think it is more likely that we just don’t understand physics, and that certain conditions can produce giant molecules like DNA, just like stars produce giant atoms. There is also a branch of mathematics known as Ramsey Theory, that is simply astonishing, and imposes structure on real-world systems, that simply must be there as a function of scale. There could be unknown results of Ramsey Theory, there could be unknown physics, probably both, but I don’t need to know what’s truly at work, since I don’t think it’s credible to say that e.g., DNA is “randomly generated”, as it’s so unlikely as popularly stated, that it’s unscientific.
Finally, in this view, we can make a distinct and additional connection between complexity and sentience, since we all know sentience is real, subjectively, and so it must have an objective cause, which could have something to do with complexity itself, since it seems to exist only in complex systems. Specifically, that once a system achieves a given level of complexity, it gives rise to sentience, as an objective phenomenon distinct from e.g., the body itself. This is not unscientific thinking at all, since it should be measurable, and we already know that certain living systems give rise to poorly understood fields, that are nonetheless measurable. Sentience would in this view be a field generated by a sufficiently complex system, that produces what we all know as a subjective experience of reality itself.
