The electromagnetic spectrum appears to be arbitrarily divisible. This means that for any subset of the spectrum, we can subdivide that subset into an arbitrarily large number of intervals. So, for example, we can, as a theoretical matter matter, subdivide the visible spectrum into as many intervals as we’d like. This means that if we have a light source that can emit a particular range of frequencies, and a dataset that we’d like to encode using frequencies of light from that range, we can assign each element of the dataset a unique frequency.
So let’s assume we have a dataset of 

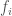
If we shine two beams of light, each with their own frequency, through a refractive medium, like a prism, then the exiting angle of those beams will be different. As a result, given an input vector, and a dataset of vectors, all of which are then encoded as beams of light, it should be very easy to find which vector from the dataset is most similar to the input vector, using some version of refraction, or perhaps interferometry. This would allow for nearest-neighbor deep learning to be implemented using a computer driven by light, rather than electricity.
I’ve already shown that vectorized nearest-neigbor is an extremely fast, and accurate method of implementing machine learning. Perhaps by using a beam-splitter, we can simultaneously test an input vector against an entire dataset, which would allow for something analogous to vectorization using beams of light.
