I came up with a measure of rank correlation when I was living in Sweden, that I abandoned because I was working on A.I. and physics, and it turns out, I could use it, in order to calculate the correlation between confidence and accuracy. A user on Reddit pointed out to me that something similar is already known, named the Kendall Tau Rank Correlation. The difference between what I still believe to be an original measure of correlation, and the Kendall Tau measure, is that Kendall’s measure counts the number of unequal ordinals. In contrast, my measure takes the difference between corresponding ordinals, treating them as cardinal values, for this purpose (i.e., it’s not just that 3 is unequal to 5, it’s that the absolute difference is 2). As a result, if the sorting process moves an entry from the front of the list to back of the list, that’s a measurably bigger change, than moving that entry by one index. Putting aside the question of whether or not my measure is original, something truly strange has again appeared on my radar, and I ignored it the first time because I had too much to do:
Applying my measure, a list in random order, is closer to backwards, than forwards, as measured by rank correlation.
To unpack this, when you calculate rank correlation, what you’re doing is, taking two lists of numbers, sorting one, and using the resultant permutation of ordinals, to sort the second list of numbers. So for example, given (i.e., the domain) and (i.e., the range), sorting the range will produce the permutation-vector , in that the position of the first entry of is unchanged in the sorted list of , the position of the second entry of has moved to the fourth entry of the sorted list of , and so on. My understanding is that Kendall Tau counts the number of unequal ordinals, so we would in this case compare, entry by entry, the vectors . In that case, the second and fourth entries are unequal, with two entries contributing to our measure of correlation. Note that if two vectors are perfectly correlated, then the ordinals will not change, and so we would count a score of zero, all scores over zero therefore indicating a less than perfect correlation.
When calculating my presumably original measure of correlation, you would instead treat the ordinal values as cardinals, and so rather than count the number of discordant pairs, you would take the absolute value of their differences. So rather than comparing corresponding entries for equality, you would instead take the absolute value of the difference between corresponding vectors , and then take the sum, producing . As a consequence, position matters, and moving an entry, e.g., from the front of a list to the back is more significant, than a slight change in position.
So a backwards list would cause us to take the sum over the difference between the vectors , which is given by Gauss’ formula.
That’s not the interesting part –
The interesting part is, let be the value of , given a number of items in reverse order (i.e., is the value of , given elements, in a backward list). Now posit a random list, i.e., generate a randomly permuted list using a random number generator, and take the ratio of the value , given that list, divided by . Or, you can also take a linear function and incrementally scramble it, you find in both cases:
The ratio seems to converge to , as a function of .
This suggests a random list is closer to backwards than sorted, using this metric.
There could be some basic math I’m missing, but this is interesting.
Specifically, both a perfectly sorted list and a perfectly backwards list have trivial Kolmogorov Complexities, and so, you would expect, intuitively, a random list to fall equally between the two, but this is just wrong, as it is plainly the case that when the rank correlation of a random list, is divided by the rank correlation of a backwards list, the ratio is roughly , suggesting a random ordering is closer to a backwards list, than a forward sorted list. Again, both a forward sorted list and a backward sorted list have a trivial complexity:
I’m obviously working on the Pro Version of my AutoML software, Black Tree AutoML, and most of the work is simply restating what I’ve done in a manner that interacts with the GUI I’ve developed (pictured below). This in turn causes me to reconsider work I’ve already done, and so I thought it worthwhile to present again my basic views on Machine Learning, nearly six years after I started working on A.I. and Physics full-time, as they’ve plainly evolved quite a bit, and have been distilled into what is, as far as I know, humanity’s fastest Deep Learning software.
Basic Principles
In a series of Lemmas (see, Analyzing Dataset Consistency [1]), I proved that under certain reasonable assumptions, you can classify and cluster datasets with literally perfect accuracy (see Lemma 1.1). Of course, real world datasets don’t perfectly conform to the assumptions, but my work nonetheless shows, that worst-case polynomial runtime algorithms can produce astonishingly high accuracies:
Dataset
Accuracy
Total Runtime (Seconds)
UCI Credit (2,500 rows)
98.46%
217.23
UCI Ionosphere (351 rows)
100.0%
0.7551
UCI Iris (150 rows)
100.0%
0.2379
UCI Parksinsons (195 rows)
100.0%
0.3798
UCI Sonar (208 rows)
100.0%
0.5131
UCI Wine (178 rows)
100.0%
0.3100
UCI Abalone (2,500 rows)
100.0%
10.597
MNIST Fashion (2,500 images)
97.76%
25.562
MRI Dataset (1,879 images)
98.425%
36.754
Table 1. The results above were generated using Black Tree’s “Supervised Delta Classification” algorithm, running on an iMac 3.2 GHz Core i5, and all datasets can be downloaded through blacktreeautoml.com, together with a Free Version of Black Tree capable of producing these results on any Mac with OS 10.10 or later.
This informs my work generally, which seeks to make maximum use of data compression, and parallel computing, taking worst-case polynomial runtime algorithms, producing, at times, best-case constant runtime algorithms, that also, at times, run on a small fraction of the input data. The net result is astonishingly accurate and efficient Deep Learning software, that is so simple and universal, it can run in a point-and-click GUI:
The GUI for the Free Version of Black Tree AutoML, available at, blacktreeautoml.com
Even when running on consumer devices, Black Tree’s runtimes are simply incomparable to typical Deep Learning techniques, such as Neural Networks, and the charts below show the runtimes (in seconds) of Black Tree’s fully vectorized “Delta Clustering” algorithm, running on a MacBook Air 1.3 GHz Intel Core i5, as a function of the number of rows, given datasets with 10 columns (left) and 15 columns (right), respectively. In the worst case (i.e., with no parallel computing), Black Tree’s algorithms are all polynomial in runtime as a function of the number of rows and columns.
Data Clustering
Spherical Clustering
Almost all of my classification algorithms first make use of clustering, and so I’ll spend some time describing that process. My basic clustering method is in essence really simple:
1. Fix a radius of delta (I’ll describe the calculation below);
2. Then, for each row of the dataset (treated as a vector), find all other rows (again, treated as vectors), that are within delta of that row (i.e., contained in the sphere of radius delta, with an origin of the vector in question). This will generate a spherical cluster, for each row of the dataset, and therefore, a distribution of classes within each such cluster.
The iterative version of this method has a linear runtime as a function of , where is the number of rows and is the number of columns (note, we simply take the norm of the difference between a given vector, and all other vectors in the dataset). The fully vectorized version of this algorithm has a constant runtime, because all rows are independent of each other, and all columns are independent of each other, and you can, therefore, take the norm of the difference between a given row and all other rows, simultaneously. As a result, the parallel runtime is constant.
Calculating Delta
The simplest clustering method is the supervised calculation of delta: you simply increase delta, some fixed number of times, using a fixed increment, until you encounter your first error, which is defined by the cluster in question containing a vector that is not of the same class as the origin vector. This will of course produce clusters that contain a single class of data, though it could be the case, that you have a cluster of one for a given row (i.e., the cluster contains only the origin). This requires running the Spherical Clustering algorithm above, some fixed number of times, and then searching in order through the results for the first error. And so for a given row, the complexity of this process is, in parallel, , again producing a constant runtime. Because all rows are independent of each other, we can run this process on each row simultaneously, and so you can cluster an entire dataset in constant time.
What’s notable, is that even consumer devices have some capacity for parallel computing, and languages like Matlab and Octave, are apparently capable of utilizing this, producing the astonishing runtimes above. These same processes run on a truly parallel machine would reduce Machine Learning to something that can be accomplished in constant time, as a general matter.
Supervised Classification
Now posit a Testing Dataset, and assume we’ve first run the process above on a Training Dataset, thereby calculating a supervised value of delta. My simplest prediction method first applies the Nearest Neighbor method to every row of the Testing Dataset, returning the nearest neighbor of a given vector in the Testing Dataset, from the Training Dataset. That is, for an input vector A in the Testing Dataset, the Nearest Neighbor method will return B in the Training Dataset, for which is minimum over the Training Dataset (i.e., B is the Training Dataset vector that is closest to A).
The next step asks whether . If that is the case, then the vector A would have been included in the cluster for vector B, and because the clustering algorithm is supervised, I assume that the classifiers of A and B are the same. If , then that prediction is “rejected”, and is treated as unknown, and therefore not considered for purposes of calculating accuracy. This results in a prediction method that can determine ex ante, whether or not a prediction should be treated as “good” or “bad”.
I proved in [1], that if a dataset is what I call “locally consistent”, then this algorithm will produce perfect accuracy (see Lemma 2.3 of [1]). In practice, this is in fact the case, and as you can see, this algorithm produces perfect or nearly perfect accuracies for all of the datasets in Table 1 above.
Confidence-Based Prediction
Modal Prediction
In the example above, we first clustered the dataset, and then used the resultant value of delta to answer the question, of whether or not a prediction should be “rejected”, and therefore treated as an unknown value. We could instead look at the contents of the cluster in question, for information regarding the hidden classifier of the input vector. In the case of the supervised clustering algorithm above, the class of all of the vectors included in the cluster for B are the same, since the algorithm terminates upon discovering an error, thereby generating clusters that contain vectors of internally consistent classes. We could instead use an unsupervised process, that utilizes a fixed, sufficiently large value of delta, to ensure that as a general matter, clusters are large enough to generate a representative distribution of the classes near a given vector. We could then look to the modal class (i.e., the most frequent class), in a cluster, as the predicted class for any input vector that would have been included in that cluster.
This is the process utilized in my Confidence-Based Prediction algorithm, though there is an additional step that calculates the value of Confidence for a given prediction, which requires a bit of review of very basic information theory. Ultimately, this process allows us to place a given prediction on a continuous scale of Confidence, unlike the method above, which is binary (i.e., predictions are either accepted or rejected). This in turn allows a user, not the algorithm, to say what predictions they would like to accept or reject.
Calculating Confidence
In another paper (see, Information, Knowledge, and Uncertainty [2]), I introduced a fundamental equation of epistemology, that connects Information (I), Knowledge (K), and Uncertainty (U), using the following equation:
This simply must be the case, since all information about a given system is either known to you (your Knowledge), or unknown to you (your Uncertainty). It turns out that using the work of Claude Shannon, we can calculate U exactly, which he proved to be proportional to the Shannon Entropy of the distribution of states of a system (see Section 6 of, A Mathematical Theory of Communication [3]). Using my work in information theory, you can calculate I, which is given by the logarithm of the number of states of a system (see Section 2 of [2]). This in turn allows us to calculate Knowledge as the difference between these two quantities,
I’ve shown that we can apply this equation to Euclidean vectors that contain integer values, in particular, an observed distribution of classes within a cluster (i.e., a vector of class labels) (see Section 3 of [2]). Since the modal prediction process above maps each row of a dataset to a cluster, we can then consider the related vector of classes (i.e., the classes of each row in the cluster), and therefore, assign a value of Knowledge to each row of a dataset.
Probabilities of course exist over the interval of the Reals, whereas the formula for Knowledge above is unbounded over the Reals. We can, however, normalize the values of Knowledge for a given dataset, by simply dividing by the maximum value of Knowledge over the rows of the dataset, which will of course, normalize these values of Knowledge to the interval.
I’ve also shown that modal prediction is more reliable as a function of increasing Knowledge and increasing modal probability (see Graph 1 below). That is, as both the modal probability of a given prediction, and the Knowledge associated with the underlying vector of classes, increase, the accuracy of the prediction also increases. This in turn implies the following equation for Confidence,
Where is the modal probability of a prediction, and is the normalized value of Knowledge of the prediction.
Accuracy as a function of Confidence (not normalized, the x-axis shows the iteration number, with Confidence increasing each iteration) for the UCI Credit Dataset.

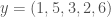
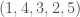

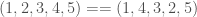
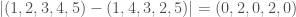






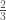




 , where
, where  times, and then searching in order through the
times, and then searching in order through the  , again producing a constant runtime. Because all rows are independent of each other, we can run this process on each row simultaneously, and so you can cluster an entire dataset in constant time.
, again producing a constant runtime. Because all rows are independent of each other, we can run this process on each row simultaneously, and so you can cluster an entire dataset in constant time. is minimum over the Training Dataset (i.e., B is the Training Dataset vector that is closest to A).
is minimum over the Training Dataset (i.e., B is the Training Dataset vector that is closest to A). . If that is the case, then the vector A would have been included in the cluster for vector B, and because the clustering algorithm is supervised, I assume that the classifiers of A and B are the same. If
. If that is the case, then the vector A would have been included in the cluster for vector B, and because the clustering algorithm is supervised, I assume that the classifiers of A and B are the same. If 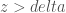 , then that prediction is “rejected”, and is treated as unknown, and therefore not considered for purposes of calculating accuracy. This results in a prediction method that can determine ex ante, whether or not a prediction should be treated as “good” or “bad”.
, then that prediction is “rejected”, and is treated as unknown, and therefore not considered for purposes of calculating accuracy. This results in a prediction method that can determine ex ante, whether or not a prediction should be treated as “good” or “bad”.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) scale of Confidence, unlike the method above, which is binary (i.e., predictions are either accepted or rejected). This in turn allows a user, not the algorithm, to say what predictions they would like to accept or reject.
scale of Confidence, unlike the method above, which is binary (i.e., predictions are either accepted or rejected). This in turn allows a user, not the algorithm, to say what predictions they would like to accept or reject.


 is the modal probability of a prediction, and
is the modal probability of a prediction, and 
