I’ve already introduced a new model of A.I. that allows for autonomous real-time deep learning on cheap consumer devices, and below I’ll introduce a new algorithm that can solve classifications over datasets that consist of tens of millions of observations, quickly and accurately on cheap consumer devices. The deep learning algorithms that I’ve already introduced are incomparably more efficient than typical deep learning algorithms, and the algorithm below takes my work to the extreme, allowing ordinary consumer devices to solve classification problems that even an industrial quality machine would likely struggle to solve in any reasonable amount of time when using traditional deep learning algorithms.
Running on a $200 dollar Lenovo laptop, the algorithm correctly classified a dataset of million observations comprised of points in Euclidean 3-space in 10.12 minutes, with an accuracy of 100%. When applied to a dataset of million observations, the algorithm classified the dataset in 52 seconds, again with an accuracy of 100%. As a general matter, the runtimes suggest that this algorithm would allow for efficient processing of datasets containing hundreds of millions of observations on a cheap consumer device, but Octave runs out of memory at around 15 million observations, so I cannot say for sure.
All of this work is derived from the algorithms that I described in a brief note, yesterday, but the clustering algorithm itself is the same clustering algorithm that I introduced about a year ago, which is rooted in information theory: I’ve simply replaced the operator in the original algorithm with one that lends itself to efficient comparison of mass-scale observations.
All of the code necessary to generate the dataset, and apply the algorithm, is attached below.
Comparing Mass-Scale Observations
The core idea is that the dataset consists of elements that have plainly different categories, when expressed as real world objects, but that the elements contain so many observations, that uncovering this fact would be intractable, at least when using traditional machine learning techniques. Even using my typical clustering algorithms, which always have a low-degree polynomial runtime, these problems are not tractable on a consumer device, but could probably be solved on a commercial grade machine.
We can easily imagine these types of real-world problems: for example, you could have a high-resolution sensor that produces an enormous number of observations, tasked with discerning between two plainly different physical objects. To a human observer, the distinction would be trivial, but to a machine that is flooded with hundreds of millions of observations, this task is probably intractable using traditional machine learning techniques, for the simple reason that there is just too much information to sift through in order to uncover what could be a simple structure in the dataset.
The intuition that I noted yesterday, that underlies the operators that I’ve developed, is that by simply sorting a dataset, we can uncover a lot of amount of information about the dataset.
Let’s consider the most basic case, of two enormous sets of floating point numbers, that both contain the same number of items. Further, let’s assume that a human observer would, upon inspection, conclude that the two sets of numbers are similar, in that randomly selecting numbers from the two sets produces roughly the same distribution of numbers. It follows that if we sort these two sets of numbers, then at each ordinal entry in the two sorted lists, we should find roughly comparable numbers. This seems like a trivial insight, but if instead we consider two drastically different sets of numbers, then this won’t be true, since the minimum, maximum, and everything in between, will be drastically different in value, causing corresponding ordinal entries to differ significantly. As a result, by simply taking the sum over the square of the difference between corresponding entries in two sorted lists of numbers, we can construct a meaningful measure of the difference between the two sets of numbers.
The most important aspect of this approach, is that sorting, and taking summations, over even tens of millions of observations can be done in seconds in languages like MATLAB and Octave. This allows us to quickly compare the difference between two enormous sets of numbers. We can, therefore, also take an enormous set of vectors, sort each dimension, and apply the same technique, separately, to each dimension, thereafter taking the sum over the result for each dimension, thereby producing a measure of total difference between two enormous sets of vectors. We can then treat this entire process as an operator that is applied to two sets of vectors, and use it as the primary operator in my “within-delta” clustering algorithm.
Note that I have in other cases, also used other operators, such as the intersection operator, and so the approach to A.I. that I introduced about a year ago is truly general, and can be applied to non-Euclidean spaces. But in this case, we are substituting the norm operator for reasons of efficiency, even though the data is itself Euclidean, which would ordinarily warrant use of the norm operator.
Identifying Macro-States of a Thermodynamic System
We can now consider a simple example of a system comprised of particles of gas trapped in a volume, where each observation of the system consists of points in Euclidean 3-space. The dataset contains observations, for a total of million points in Euclidean 3-space. It is simply not possible to classify data on this scale using traditional machine learning techniques in any short amount of time, especially on a cheap laptop.
The actual classification task is simple: in one class of states, the gas is compressed in a small volume, and in the other, the volume expands, allowing for a broader set of possible positions for the particles. To a human observer, the distinction between these two states would be obvious, assuming you could observe the macroscopic boundaries of the volume. But to a machine that’s being given sensor data, that in this case generates tens of millions of observations, it will probably not be possible to classify this data using any technique that requires significant manipulation of the underlying point data, absent significant amounts of time. As a result, this example highlights the power of this approach, which allows machines to identify well defined categories in enormous datasets, the sheer size of which obfuscates the categories.
Though the classification question is in this case simple, the actual difference in volume between the two categories is certainly not extreme: one category is a cube bounded within [0,1] in all three dimensions, and the other is a cube bounded within [0, 1.25] in all three dimensions. As a result, this algorithm is almost certainly useful for a wide variety of real-world classification problems that involve an otherwise intractable number of observations.
OCTAVE CODE
My core A.I. library, which includes all background functions, is available here.
I’m in the middle of writing a formal paper and related software on automated hypothesis testing, but I thought I’d outline the basic idea, which is that information theory can be used to provide an absolute context in which error is evaluated to determine whether a hypothesis is exact, imprecise, or simply incorrect. I explained the basic idea on Twitter last week, which is that every observation carries a certain amount of information, and because length itself can be associated with information, we can therefore measure the net information of a hypothesis as the difference between (x) the information content of an observation less (y) the information content of the error between the observation and the hypothesis.
Error, Length, and Information
I’ll present a more fulsome discussion of this topic in a formal research paper I’m working on, but in short, any physical system can be used to store information, so long as you can identify and control its states. As a result, a physical system that can be in any one of states can be used to represent characters, or any other set of distinct elements. As a practical example, just imagine a dial that you rotate, that has settings. This is a physical system that can be in any one of states, and therefore, has the same storage capacity as binary bits. The same is true of a shoe box – either the lid is on, or it isn’t, and as a result, a shoe box is a physical system that has two states, and can store bit of information. This is not how normal people think about the world, but it is how an information theorist should, in my opinion.
Now consider a line with a point upon it at some location. Each possible location for the point will represent a unique state of this system. And of course, the longer the line is, the more possible locations there will be for the point, producing a system that has a larger number of states as the length of the line increases. Again, this is not how normal people think about lines, since they’re primarily conceptual devices imposed upon empty spaces, or objects, and not technically “real”. But, if you had, for example, some string, and a piece of glitter, you could use this system to store information. As a practical matter, if the string is unmarked, it will be hard for you to tell the difference between the possible locations for the speck of glitter along its length. To remedy this, you could mark the string with equally spaced lines that indicate the beginning of one segment and the end of another. Though this is decidedly primitive, a string with etchings on it together with a piece of glitter can literally store bits of information.
As a practical and theoretical matter, there will be some minimum length, below which, you cannot measure distance. That is, your vision is only so good, and even if you have the assistance of a machine, its resolution will still be finite. Therefore, in all circumstances, there will be some minimum length that is the minimum segment size into which you can divide any length. As a result, when presented with a line of length , the maximum number of possible discernible locations along its length upon which you could place an object is given by,
Similarly, there will be some practical limit to the number of objects that you can place upon any given line, and as a result, the maximum number of states that can be generated by placing objects upon any given line is . Therefore, the information capacity of a system comprised of points along a line is given by,
For any given observer in a particular context, the values of and will be fixed. As a result, the information capacity of a line is really a function of the length of the line, since the other two parameters will be fixed, both as a practical and theoretical matter. This equation is supported by the fact that you can encode any vector with a norm of using bits. For example, if we want to express a vector in two-space, we need to specify only the length of the vector, which requires bits, and the angle the vector forms with either the horizontal or vertical axis. Because the angle does not change as a function of the norm of the vector, it requires a constant amount of information to represent, resulting in a total number of bits given by bits. Though this is the amount of information required to represent a vector, which is distinct from the amount of information that a vector can store, in reality, these two numbers are the same for any physical system, if we don’t make use of compression in the representation.
As a result, every error, which will be the norm of the difference between two vectors , will be associated with an amount of information given by,
To make things more concrete, let’s consider an example involving a given observed level of RGB luminosity . Now let’s suppose we are told by a third party that the level of luminosity is hypothesized to be . The error in this case is given by,
and therefore, the information associated with the error is The net information of the hypothesis is given by,
.
I’ve chosen in part because capital is associated with information through Shannon’s equation for entropy. This equation allows us to distinguish between exact, imprecise, and incorrect answers, since is either equal to , less than but positive, or negative. As a simple example, the following is Octave code that takes a given observed luminosity as input, and iterates through increasing hypothetical luminosities from , until it produces an incorrect hypothesis, using the criteria above.
The software that powers my deep learning engine Prometheus is already public, and so are the related academic papers, but putting it all in one place, in plain English, adds value, particularly to commercially interested, non-experts. And so I’ve put together a short pitch deck, attached below.
Feel free to send this around to anyone that might be interested in investing in the product, or leasing a commercial version of the software.
Though high school students make routine use of real numbers, it is in fact a strange set of numbers, that I personally struggle to understand rigorously. In particular, I think it’s a tall order to construct a physically intuitive model of the real numbers, despite their rather suggestive label, “real”, forcing mathematicians to at least entertain the idea that they in fact correspond to some aspect of our physical reality.
The work of Georg Cantor shows that if the real numbers are in fact physically real, then we are living in a truly strange place, where systems could contain themselves, be arbitrarily divisible, yet nonetheless stay the same size, and these are just a few of the bizarre properties of infinite sets that he showed must exist, if we posit the existence of infinity in the first instance, and accept some primordial, and therefore, difficult to escape notions of mappings between sets.
But there is a property of the reals that is not shared by the integers, which I’ve used to define a set of numbers I call the inarticulable numbers. These are numbers that, by virtue of the cardinality of the set of real numbers, simply cannot be expressed in any finite statement of symbols. Non-computable numbers are a common topic among computer scientists, which again must exist simply by virtue of the cardinality of the real numbers. In short, there are only countably many programs, and because there are uncountably many reals, there simply aren’t enough programs to calculate all the reals. This means that some reals simply cannot be calculated on a UTM. But we can nonetheless specify and define rigorously some non-computable numbers, such as the Chaitin numbers, which despite being non-computable, can nonetheless be defined and identified by a finite equation.
In contrast, what I call inarticulable numbers are a set of numbers that cannot be specified by any finite equation. Because every program can be expressed as a sequence of mathematical operations, it follows that if a number is inarticulable, then there cannot be any program that generates it, since that would be tantamount to an equation that specifies the number. As a result, if a number is inarticulable, it is therefore non-computable. Inarticulable numbers must exist, since any human language for doing mathematics will consistent of finite statements. This means that even if our alphabet is infinite, which, e.g., the integers are, the statements that express the math to be done must be finite, in that we can write only a finite number of etchings on a page before we die. It’s really that simple.
As a result, it must be the case that there is a subset of the real numbers comprised of numbers that are not only non-computable, but also incapable of definite expression in a written human language. Because there are only countably many finite expressions over any given finite or countable alphabet, it follows that the complement of the set of inarticulable numbers (i.e., the numbers that can be expressed in a finite statement) is countable, which implies that the set of inarticulable numbers is uncountable. In plain English, basically all of the real numbers defy definite expression in a written human language.
This is a shocking conclusion, in my opinion, because it shows that it’s not just computation that is incapable of expressing most real numbers – it’s written human language itself. The most advanced means by which human beings can describe the external world is through the language of mathematics. And it turns out, that even our greatest and most expressive means of description is incapable of describing basically all real numbers. This means that if real numbers are in fact real, then we can’t describe most of what’s around us, implying that the portion of information about the external world described by our written descriptions of its machinations is effectively zero.
All of this is completely true, in the sense that this follows from the application of logic to the basic premises of mathematics, so you can either take issue with logic or very primordial assumptions about the operations of mathematics, or you can accept what I’ve said above, which I believe to be true, because despite being very conscious of my limitations as a human being, I nonetheless believe that believing in logic and mathematics is the most productive way to exist.
That said, I spend a lot of time thinking about the nature of computation that goes beyond the power of a Turing Machine, and if we are going to make use of most of the real numbers as a physical matter, then we’ll have to learn how to do exactly that – which is to build a machine that is categorically superior to a UTM. This means developing a language that goes beyond the limits of written language, since as I’ve shown above, most of the reals defy definite expression in a written language. It turns out, human beings have spent a significant amount of their time developing a different language that might make the cut, and this is the language of art, where symbolism in particular, could serve as a pointer to an otherwise inarticulable quantity. That is, even though I can’t write down an equation for a given inarticulable quantity, I can still assign it a label, and if both you and I have observed the same inarticulable quantity, we can both agree to call it “blue“.
In two previous articles (Part I, and Part II), I presented a mathematical model of coincidence, rooted in Carl Jung’s notion of synchronicity. Part I discussed some of the basic mathematics and concepts, and Part II showed how these concepts can be used as a practical way to deliver messages to a recipient that is not expecting to receive a message. There is a lot of information in the prior articles, but it is nonetheless possible to read only this article, and still understand what’s going on, so I’ll begin by revisiting the following definition of coincidence:
If I had to define coincidence, I would say it has two components: (a) a low probability, and (b) contextual relevance.
One of the examples of coincidence I gave in the original article on the topic is the following:
Imagine walking out of a store having just purchased a bright orange hat, when suddenly, someone throws an orange at you. Both events are low probability in the ordinary course, and the latter event of getting hit by an orange is relevant, because it intersects in property with the item you just purchased. And you would be completely certain the event was deliberate, even if it seemed superficially impossible for that to be the case.
This definition formalizes the difference between something that is merely unlikely, and something that is both unlikely, and also directed at you, in a manner that lends itself to measurement, since you can measure both the probability of the event in question, and the extent to which it intersects with your life experiences and expectations, though the latter will of course involve some judgement, the mechanization of which will introduce some imprecision. But the point is, this formalization allows us to turn coincidence into a mathematical concept that can be used as a tool to deliver messages to recipients that are not expecting to receive a message.
The following is an example I gave in the previous article, that highlights the difference between an unlikely event, and a coincidence, as I’ve defined it:
[It’s] the difference between seeing super model Amber Valletta walking through the streets of New York City, and instead seeing super model Amber Valletta wearing a t-shirt with your face on it. The former is an unlikely event, whereas the latter event is not only unlikely, but also personal, since she’s wearing a t-shirt with your face on it, suggesting the circumstances are almost certainly the product of design, and not the product of the undisturbed operations of nature.
Delivery of the message is effectuated by orchestrating a coincidence that first gets the attention of the recipient, and in Part II, I presented the outlines of how you can encrypt not only the attention-getting coincidence, but also the message that follows. The net result is that you can deliver an encrypted message in plain sight, in public, and as a general matter, only the intended recipient will receive and understand the message.
In this article, I’m going to present a practical, mathematical model of human association, and ultimately, two mathematical languages on sets: one based upon the union operator, and another based upon the intersection operator. Both languages can be used to convey messages to recipients that don’t expect to receive a message, provided a coincidence is orchestrated to garner the recipient’s attention. Though technically independent of coincidence, by combining these languages with the use of coincidence, we can develop a rigorous mathematical model of how to deliver an encrypted message to a recipient that is not expecting a message, in a mechanized manner, in plain sight, publicly, and as a general matter, no one will know who the intended recipient is, or the contents of the message, other than the intended recipient.
THE PRACTICAL MECHANICS OF ASSOCIATION
Signals and Mappings
Association is, in its most fundamental form, a mapping from an input stimulus to some stored memory. For example, if I see an orange, I’ll probably conjure memories about oranges, perhaps imagining the last orange I ate, or the Matisse painting in my old apartment, featuring three oranges. In both instances, I’ve taken an input signal, i.e., an actual physical orange, and mapped it to some set of memories. As a result, we’ll need some method of comparing an exogenous input signal to what’s in memory in order to produce associations. If we imagine this taking place on a machine, rather than in human memory, we can easily think of practical ways to get this done. For example, by scanning a dataset of images for an orange, and returning every image that contains an orange as part of an association cluster. This probably isn’t the result we ultimately want, but it works as a simple example of mechanized human psychological association.
How to analyze exogenous signals like images is a well-understood topic in A.I., and if you’re interested in my views on the subject, this article on vectorized image processing provides a solid overview on my approach to A.I., which is to use information theory and computer theory to give objective answers to questions of discernment and observation. In contrast, the main focus of this article is how to manipulate associations to deliver messages, and so I’ll assume that signals can be analyzed and mapped to a dataset by a predefined algorithm. This means that the approach discussed in this article will be agnostic on how you perceive an orange, and what you associate with an orange, treating your perceptions and associations as fixed, and known to the sender. Instead, we will focus on exploiting those associations to deliver messages.
Types of Association
Though I’m sure the actual biology of association is complex, I’m going to divide association into three simple categories: similarity, observation, and intersection. There are other mechanics that can generate an association in someone’s mind (e.g., unconscious instinct), but the goal is to develop a model that works as a means of communication, and covers how people actually think, and construct meaning, generally.
Association by similarityis intended to cover cases where two signals are sufficiently similar to be considered associated with one another. For example, when presented with two pictures of sufficiently similar faces, it’s reasonable to make a mental association between the two, since each will likely trigger a memory of the other upon observation.
Association by observation is intended to cover cases where signals are associated because they occur proximately in time, space, or both time and space. So, for example, if a screen displays colors randomly, and blue is always almost immediately followed by green, then you’ll probably make a mental association between blue and green. Note that unlike association by similarity, there is no mathematical operator that compares the signals in question. That is, the signals are associated by virtue of their proximity in time and space, rather than any endogenous aspect of the two signals. As a result, association by observation allows for a much wider set of associations than association by similarity, since you can, in theory, cause any two objects or ideas to become associated with each other, simply by causing them to be repeatedly proximate in time and space.
Association by intersectionis intended to cover cases where signals are associated because they share some common property. This is the case covered by the original example of coincidence provided above, where the orange hat is tacitly associated with the orange fruit projectile. This is because both objects share the property of being orange in color. In this case, there is a comparison between the two objects in question, but it is not a Euclidean measure. Rather, it’s probably best thought of as implemented using an intersection operator as applied to a set of characteristics. So returning to the example, the orange hat has a set of properties, which might include, e.g., “woolly”, “plush”, and of course, “orange”. The orange fruit has a set of properties which might include, e.g., “acidic”, “firm”, and, of course, “orange”. When we apply the intersection operator to these two sets of properties, we’ll get the property of being orange in color, thereby triggering an association.
In this article, I’m going to use these definitions only as a tool to think more meaningfully about associations, but in a follow up article, I’ll present a rigorous mathematical treatment of each category of association, together with related software. For those that can’t wait, association by similarity is pretty easy to implement, especially using my notion of “within-delta”, which you can read about in my original paper on A.I. Association by observation can be implemented using variants of my projectile tracking software (just test for proximity in time, space, or, time and space), and implementing association by intersection is trivial.
Modeling Associations
To formalize and implement this approach, we’ll need three components: a signal, an observer, and a dictionary. A signalcan be any finite collection of exogenous sensory data, from a t-shirt, to a car crash. An observeris a human being that will observe a signal, and map it to some dictionary, which is a finite collection of bundles of stored sensory information, indexed by integers.
So, for example, I could show you an orange. In this example, the signal is the orange, the observer is you, and the dictionary is your memory, which we’re going to treat as an integer-indexed collection of bundles of sensory data. Further, we’ll assume that upon seeing the orange, an association cluster is produced by your mind, which we’ll model as a set of integers, representing the indices of the dictionary entries triggered by observing the input orange.
In reality, seeing an orange will probably generate something that is better modeled as a discrete graph, where we can imagine the input orange itself in the center, and then as you proceed away from that central node, you get more remote associations. So, right next to the input orange node, you’d have things that are immediately associated with an orange, like its scent, taste, and color, whereas further out, you might have paintings that involve oranges. While this type of granularity is probably important in designing software that simulates human behavior, it is not important to the design of software that delivers messages based upon associations. That is, even if we capture only a crude set of likely associations, this will probably work just fine for what we’re doing, which is sending messages, not building robots.
I’m assuming that we already have software that can process the signal, and produce an association cluster, and so the goal will be to design software on top of that, to send messages using the recipient’s associations, which are assumed to be fixed, and known to the sender. Even though consumer behavior is a heavily studied topic, writing software that actually maps signals to associations is certainly not a trivial task. But the reality is, there’s so much consumer and social media data available, that this problem has almost certainly been solved.
DELIVERING MESSAGES USING ASSOCIATIONS
Signal and Association
Formalizing what we’ve described a bit more, every exogenous signal will be mapped to some association cluster , where each is an integer that corresponds to some bundle of sensory information in the dictionary, each of which is really just a memory. As a practical matter, the dictionary would be modeled on the sender-side by an integer-indexed table of pointers that reference what could be various forms of media, including images, sounds, words, etc. This means that an entry in the dictionary would point to something similar to what the recipient actually conjures upon observing the signal. So, for example, if I show you an orange, my model of your associations would probably include photos from your social media accounts that are related to oranges. This is actually astonishing when you think about it, because it means that companies can literally look into your actual mental associations, which probably include photos from your social media libraries – let that sink in.
Two Primal Languages on Sets
Let’s assume that we’ve already gotten the recipient’s attention using a coincidence, and would now like to convey a message using a set of signals . For simplicity, we’re going to assume that the signals are not context dependent, and are not sensitive to order. That is, the associations triggered by are always the same, regardless of whether I deliver that signal alone, or in the context of a larger set of signals. This is not how most human languages work, since language is generally sensitive to context. Instead, what I’m going to define are two primal, symbolic languages, one rooted in the intersection operator, and the other rooted in the union operator. These will ultimately produce something like context, but the point is that the associations generated by the individual signals are not sensitive to context, whereas the overall meaning of the signal will be sensitive to the total set of signals delivered.
Expressed mathematically, stating the meaning of a set of signals in each language is straightforward. Specifically, the meaningof over the language of intersections is,
,
and the meaning of over the language of unions is,
.
That is, the meaning of over the language of intersections is the intersection over the set of associations for the signals in . In plain English, it’s the associations that all of the signals have in common. The meaning of over the language of unions is the union over the set of associations for the signals in , which in plain English, is the combined, accumulated set of associations over all of the signals. In each case, is a set of integers that resolves to a collection of bundles of sensory data, implying that the meaning of the sequence is, in each case, ultimately a collection of memories. But because each set of associations is modeled as a set of integers, calculating can be done extremely efficiently.
Note that this is visceral meaning, not linguistic meaning, in that what is ultimately conveyed is raw sensory information that is intended to have an abstract, net effect on the recipient of the message. In some sense, these languages are more powerful than mere words, because what you can conjure in the mind of the recipient is that which hits you hardest – the face of someone you love, the blouse they wore the last time you saw them, the color of their iris, the details of their eyelashes. These are the things that words are intended to describe, whereas these languages provide a means to reference them directly, creating a mechanized, psychological portrait of raw sensory information in the mind of the recipient, that can nonetheless resolve to a single coherent meaning.
As an example, assume that is a set of images of your mother, which might include other people, but the point is that all of the images feature your mother. Under the language of intersection, the meaning will quickly converge to the notion of your mother, but the way in which it will happen will be incredibly personal, and will not only make you think of your mother’s appearance, but also how she made you feel, and perhaps other attendant nuance that is going to make the resultant meaning far more intimate than someone simply writing your mother’s name on a piece of paper. In contrast, in the language of unions, this sequence will arguably have no coherent meaning at all, since it will diverge to an unbounded set of associations, since the images include other people and things. This example shows that, not only are these two languages potentially incredibly powerful tools of communication, they are also objectively distinct languages, in that some collections of signals are meaningless in one language, yet meaningful in the other language.
With these ideas, we can now think rigorously about whether a given set of signals has a coherent meaning, by considering the rate of convergence of the cardinality of , as we calculate the intersection, or union, respectively, over . That is, if changes sizes chaotically, even when we’ve nearly exhausted all of the signals in , then it’s fair to view as, at a minimum, incomplete, since each new signal is drastically altering the ultimate set of associations. In contrast, if the size of starts to converge once we’ve exhausted most of the signals in , then it’s fair to conclude that we have received a complete message through conveyance of . The rate of convergence could of course depend upon the order in which we take the intersection or union, respectively, but we can perform this calculation multiple times, using random permutations on , and using an average, since again, we are assuming that is not a sequence, but is instead, simply a collection of signals. Note that if has a coherent meaning over the language of intersections, then it will converge to a floor cardinality, whereas if has a coherent meaning over the language of unions, then it will converge to a ceiling cardinality.
Though it’s obviously much harder to measure, what this method allows you to do is deliver two messages: returning to the example above, the meaning of over the language of intersections is the notion of your mother. If the images are truly heterogenous, then that will be the only notion left given a sufficiently long sequence of signals. However, the emotional response triggered by the images is going to turn on the particular images selected. This means that there is a second, emotional message delivered by the signals, which is arguably independent of the more literal meaning of the message over the language of intersections. For example, if the images consist of only happy memories of your mother, then the meaning of the message is still the notion of your mother, but you’ll probably feel good about observing the message. If in contrast, the images consist entirely of the most disturbing moments from her life, then the message will again be unchanged, but you’re probably going to be a little sad about it.
These languages could allow emotionally sensitive people to communicate in incredibly sophisticated ways, because it could allow for subtle changes to the same literal message due to the inclusion of different emotional triggers. This is what artists do, and this is what expert copywriters do as well – manipulate you. But, these languages could allow for a machine to study you, and color messages in a way with emotional triggers that would be simply impossible for anyone else detect. The encryption acheived if this were successful would be essentially impossible to crack. A truly sensitive person doesn’t need much – a subtle change in color, or facial expression, and the literal message is unchanged, but the emotional message might let you know the whole thing was bull shit. This means that even if social media companies know everything about your life, the inclusion of minor details could completely change the context of the message, though the literal message remains unchanged.
Two people that know each other well can do all of this without software, which is to have a conversation in front of strangers, that only the two of them truly understand, because they have private jokes, gestures, and sounds, that only the two of them truly understand. That’s not a problem, because that’s the reward for taking the time to actually get to know another human being.
The problem is, the mechanized incorporation of social media data into traditional media could allow for what would effectively be brainwashing on a mass scale, and I’m not exaggerating. Just imagine how much harm you could do during a broadcast to millions of people by simply deliberately selecting wardrobes, targeted words, people’s faces, hairstyles, images associated with news stories, even the fonts used during the broadcast, with the deliberate intent to upset viewers that have been targeted by A.I. algorithms, for whatever reason. Software of the type described above could be used to generate instructions in making these selections in a manner that maximizes harm, and minimizes evidence of wrong doing. The idea that people won’t do this is simply ridiculous – Harvey Weinstein went through far greater efforts for the unprofitable purpose of raping women. This is something that can actually make money, swing elections, or suppress competition, so, I’m certain that if it’s not already happening, it will happen.
So, while I’m proud of this work, it’s also a warning to society, that this stuff is real, and unless we regulate the media, which we used to, presumably in large part for similar reasons, we’re in serious trouble.
In a previous article, I explained how the totally unscientific topic of synchronicity can be used to produce rigorous mathematics that allows us to distinguish between a freak accident, and a deliberate signal. In short, I laid out the outlines for the mathematics that would allow you to distinguish between something that is simply unlikely, and something that is deliberately orchestrated to get your attention. In this article, I’m going to formalize this approach a bit more to show how we can use sequences of messages of this type to construct meaningful messages from a sender to an unknowing recipient. The gist is, you create an unlikely, and personal, signal, that will get an unknowing recipient’s attention, which will eventually allow you to throw targeted messages in otherwise unrelated collections of signals.
Mathematical Coincidence
Though the article is titled “On Synchronicity in Time”, what I’ve done is relabel the original concept of synchronicity as, “coincidence”, because I want to distinguish between what I’m about to introduce, which is completely scientific in nature, from the work of its source, Carl Jung, who at the time, associated what he called synchronicity with the mystical and the religious. Because I came up with the related mathematical idea of coincidence using Carl Jung’s work on synchronicity, I want to give the man a hat tip, since he was a big influence in my life, had a great mustache, and of course, I don’t want to be accused of merely tweaking a great idea, without giving credit to its original source.
If I had to define coincidence, I would say it has two components: (a) a low probability, and (b) contextual relevance.
One of the examples of coincidence I gave in the original article on the topic is the following:
Imagine walking out of a store having just purchased a bright orange hat, when suddenly, someone throws an orange at you. Both events are low probability in the ordinary course, and the latter event of getting hit by an orange is relevant, because it intersects in property with the item you just purchased. And you would be completely certain the event was deliberate, even if it seemed superficially impossible for that to be the case.
This definition allows us to construct a mathematical notion of coincidence that incorporates practical human psychology, since it distinguishes between that which is unlikely, and that which is both unlikely and personal, in a manner that can be measured. The notion of coincidence I’ve outlined above formalizes the difference between something that is merely unlikely, and something that is both unlikely, and also directed at you.
One class of examples I gave in the previous article is the difference between seeing super model Amber Valletta walking through the streets of New York City, and instead seeing super model Amber Valletta wearing a t-shirt with your face on it. The former is an unlikely event, whereas the latter event is not only unlikely, but also personal, since she’s wearing a t-shirt with your face on it, suggesting the circumstances are almost certainly the product of design, and not the product of the undisturbed operations of nature.
Personally, I think this is a really powerful idea that might help us search for life, but I’m more interested in the practical applications of this definition to signal processing, which allow us to distinguish between a freak occurrence, and a deliberate message. This is really awesome stuff, because you can get really creative with this type of messaging, ultimately building coherent statements out of totally insane components. The ultimate goal of this set of articles is to get super weird, and introduce mathematics that explains how these types of messages could be transmitted through time, without disturbing causation, creating a model of physics that allows for information to be exchanged through time, but nonetheless produces a logically and temporally consistent universe.
Public Messages with Private Recipients
A tacit assumption of the definition above is that what makes a coincidence indicative of design is the impression that the sender of the message has information about the recipient, that is included in the message. Returning to the example above, simply seeing Amber Valletta walking down the street is not enough to conclude that she deliberately walked by you, since, especially in New York City, there are plenty of other people she will also pass by on her walk. In contrast, if she is wearing a t-shirt with your face on it, then you have good reason to suspect that she walked by you, deliberately, since there is information about you memorialized in her appearance. At a minimum, such an event is indicative of design by sentience, whether or not it was Amber Valletta that hatched the plot. And again, it’s not simply the extremely low probability that suggests sentience, but rather, the intersection between the low probability event, and the life of the observer. So if instead you saw Amber Valletta wearing a t-shirt with a picture of her own face on it, that would be a strange event, that certainly carries a very low probability, that is even lower than the probability of simply seeing Amber Valletta, generally. However, it would not satisfy the definition of coincidence above, because there’s nothing personal about it, and every observer to the event will have the same experience.
In contrast, if she’s wearing a shirt with your face on it, then everyone involved will agree that the event was clearly directed at you, and no one else, and you will have a unique response to the signal. This would be a public message that is publicly directed at a particular person.
Now let’s say instead of your face, her t-shirt has a picture of your cat, and it turns out that your cat has one eye, and no left feet, at all – it drags itself only in small circles, sort of like an electron in a magnetic field. As a result, photos of your cat generally make it quite clear that the subject of the photo is in fact your cat, and not someone else’s cat, given its rather unique appearance. Upon seeing Amber Valletta, you will again be justifiably astonished, but the difference is, in this case, no one around you will understand why. That is, everyone will be happy to see Amber Valletta, people will take pictures, and they’ll probably think it’s funny that she has a demented cat on her shirt. But for you, the message will be quite different, because it will be clear that it’s your cat that’s on her shirt, which means only you will understand that the event was directed only at you, though the display was done ostentatiously, in public. This will probably be borderline disturbing, since you’ll probably have no way to explain how or why it is that Amber Valletta obtained a photograph of your cat. This would be a public message that is privately directed at a particular person.
All of this is to demonstrate that coincidence can be used to take a public signal, and turn it into a private message. Continuing with the example above, if Amber Valletta wanted to tell you something, all she would have to do is say it out loud, publicly, and you would understand that whatever she said subsequent to showing up with your demented cat on her shirt was obviously directed at you.
THE PRACTICAL MECHANICS OF ASSOCIATION
Self-Identification
As a practical matter, you have some set of life experiences and aspects that are peculiar to you. For example, your face is something that you almost certainly associate with your notion of self, whereas eating bagels is probably not, because everyone eats bagels, and unless you’re a true bagel aficionado, you’re probably not going to include bagels in your core sense of identity. Your birthday is another example, despite the fact that there are probably plenty of people that share your birthday, just like there are probably plenty of people that look a lot like you. Nonetheless, if you see the digits of your birthday written somewhere, you’ll think of yourself, just like if you see an image of what looks like what could be your face, you’ll again think of yourself.
As a result, knowing what signals a person associates with their identity allows you to deliver a public message that is privately directed at that person. This would be all the things that are uncommon enough in the population in question, but salient enough in the mind of the recipient to be recognized. The one-eyed, two-legged cat is the quintessential example of this, because it’s something that is certainly not common, at least in New York City, yet it’s something the recipient (i.e., the owner of said cat) would see every day.
The overall goal, therefore, when delivering a public message that is privately directed at a particular person, is to paint a low probability signal with an aspect that the recipient associates with themselves. So this involves understanding all the idiosyncratic aspects of life that an individual associates with themselves, and identifying those that are least common to their population, and therefore, most likely to get noticed by the individual in question. Ultimately, this approach allows you to deliver a message publicly, that is directed at a private, unknown person. But the message is itself public, so though you’ve hidden the recipient of this message, you’ve done nothing to hide the message itself.
So returning to the example above, if Amber Valletta appeared outside your bagel store, wearing a t-shirt with your one-eyed, two-legged cat on it, reciting Shakespeare’s Sonnet 18, after some initial shock and confusion, you would probably conclude that she is either insane, in love with you, or perhaps a mix of both. Though no one else would know who the intended recipient of her recitation is, the subject would likely be quickly recognized by others. The bottom line is, understanding self-identification in an unknowing recipient to a message allows you to deliver an unencrypted, public message that is privately directed at the recipient.
Private Encryption Through Association
In the example above, there is tacitly some element of association, but not really, because in all cases, there is an aspect of someone’s life that is directly referenced. In contrast, you could reference something indirectly, by association. Continuing with the example above, let’s say that your cat is a good sport, and for Halloween, you dress your cat up like a pirate, because it has one eye. As a result, if you saw Amber Valletta wearing a t-shirt with an image of a tiny, cat-sized Halloween costume, you would be pretty sure, but not totally convinced that her appearance was directed at you. If, however, her t-shirt had an image of both an ordinary cat, and the Halloween costume, you would be even more confident that her appearance was directed at you. If her t-shirt had an image of an ordinary cat, the word “eye”, and the Halloween costume, you would be nearly certain that her appearance was directed at you.
Subjectively, this is what would happen, but we can use set theory to model this process mechanically. Specifically, the tiny cat-costume intersects with your life, and because most people don’t dress their cats up like pirates, it would be reasonable to think the message is directed at you. The addition of the image of a cat makes it more obvious that what’s being referenced is a costume for a cat. Finally, the inclusion of the word “eye” makes it pretty clear that what’s being referenced is your one-eyed cat dressed like a pirate. As funny as this is, there’s math behind the mechanics, which can be modeled by taking the intersection over sets. That is, when you see the tiny cat-sized costume, you will think of your cat, but because the context isn’t totally certain, there will be other items conjured by its observation. Every additional item winnows down the set of associations, which can be modeled by intersection. It’s really no different than starting with the set , and taking iterative intersections over the sets and , which will eventually leave you with the singleton . This can be modeled with software, if you know what ideas your recipient associates with a given signal, which would allow you to deliver a sufficient number of signals to make it clear to your recipient that you are painting the event with their colors, and not someone else’s. This in turn allows you to encrypt the core identifying signal itself, since rather than simply present a picture of the particular one-eyed cat, you can instead reference the cat through disaggregated association, if you know how your recipient makes associations between signals and ideas.
Returning to the example above, imagine Amber Valletta shows up outside your bagel store, wearing a t-shirt with the cat-sized costume, a picture of an ordinary cat, and the word “eye”, holding a picture of your dead second cousin above her head, who died just a few months ago. Absolutely no one would understand what this bit of performance was intended to convey, but you would know quite plainly that she is saying that she’s going to kill your one-eyed cat. This is because the message on her shirt resolves to your cat, and the message of the dead relative, in this context, doesn’t mean anything other than death.
But we can tighten this up a bit, again using set theory. To make things simple, let’s assume that the intersection between the set of associations for the one-eyed cat, and the set of associations for the dead second cousin, is null. This means that, as a practical matter, there are no psychological associations between the one-eyed cat and the dead second cousin, which in turn suggests that they are independent components to the message. This is quite nice, because it means that we can formalize the distinction between the components of a message by taking the intersection of the associations of the components. In this case, as a practical matter, you’d say, well, the cat and my dear dead cousin Suzie don’t really have anything to do with each other, so I’m guessing those two signals are distinct. But because she just died, one fair inference is that what’s being referenced is her death. Once their independence has been established, it’s then fair to combine them, resulting in a message that conveys your one-eyed cat, and death.
THE URGENT NEED TO REGULATE SOCIAL MEDIA
This is awesome stuff, that I believe forms the basis of the mechanization of human understanding. But, it also shows quite plainly that someone can scare the shit out of you in public, if they know enough about you. The idea that people with the power, and the incentive, to do exactly this, won’t do this, is beyond naive. Social media companies are global corporations, run by boards and shareholders that are not beholden to any particular government, whose primary legal responsibility is to make money. Moreover, I’m not even sure what I’ve described above would be illegal, because the real meaning of the message exists only in the mind of the recipient, and you’d sound like a nut job trying to explain all of this to a jury. Combine this unfortunate reality with the fact that social media companies appear to be willingly facilitating illegal conduct in election rigging, terrorism, and human trafficking, and you have every reason to be suspicious of handing this kind of information over to people who have proven they are not trustworthy, and in my opinion, fundamentally, not good people.
I happen to be a mathematician, and a jerk, so it’s easier for me to make these points clear, but an ordinary person would simply suffer in private, and probably be exploited, because that’s how the world works.
TIME AND INFORMATION
Now that I’ve shown you how crappy people can use social media to intimidate others in plain sight without consequence, I’ll follow up with another article that outlines the mechanics for a completely different way of thinking about the nature of time, that allows for information to move through time in the same way that it moves through space, but in a manner that is completely consistent, without any of the nonsense you see in movies about time-travel and the like.
Carl Jung had a big influence on me when I was in college, and though these days I stick to more practical psychological considerations for application to A.I., when I was 20 years old, I was willing to entertain some radical thinking. And this is not to suggest that Jung’s ideas on psychology aren’t practical, in fact quite the opposite – personally, I believe that species memory, archetypal thinking, and a “shadow” animal nature are all very real aspects of the human condition. But Jung was unafraid to explore mystical thinking, in a manner and on a scale that is arguably unfashionable for a storied, and relatively contemporary figure in the history of Western thought. In particular, he had this idea of “synchronicity”, which I think I’ve reduced to mathematics, but I’ve called it coincidence, to dress it down a bit:
If I had to define coincidence, I would say it has two components: (a) a low probability, and (b) contextual relevance.
One of the examples of coincidence I gave in the article is the following:
Imagine walking out of a store having just purchased a bright orange hat, when suddenly, someone throws an orange at you. Both events are low probability in the ordinary course, and the latter event of getting hit by an orange is relevant, because it intersects in property with the item you just purchased. And you would be completely certain the event was deliberate, even if it seemed superficially impossible for that to be the case.
In that article, I discuss some practical explanations for why human beings are drawn to coincidence, and how information theory can help us make sense of that behavior. In short, if an event has a low probability, then it should carry a lot of information, and if our brains process signals efficiently, the proximate occurrence of two, contextually related, low probability events (i.e., a coincidence) should get a lot of attention, since it carries a lot of information, and therefore, requires a significant amount of brain power to fully process. The overall point being that even though coincidence is associated with superstition, the underlying mechanic driving the resultant behavior of being drawn to coincidence makes perfect sense in light of information theory.
So, I think I’ve explained why some people are superstitious, and why coincidence is inherently interesting to human beings, but this still leaves open the question how coincidence materializes in the physical world, which really shouldn’t have a good explanation. Though I won’t succumb to pseudoscience and claim to have an answer, I will discuss how thinking differently about the nature of time and causation can actually make sense of coincidence in a mathematically rigorous manner, which I find fascinating, and might even be a testable hypothesis, but in any case, it nonetheless presents a beautiful model of reality rooted in the theory of sets, and gives me a great excuse to discuss a bunch of art in the context of mathematics and physics, so, I’m not going to pass up that opportunity.
Expectations and Information
As a practical matter, the human brain probably operates like a modern computer, on a macroscopic level, in that there’s probably something akin to RAM that is populated with information gleaned from recent experiences. So, for example, if you buy a cup of coffee and a bagel, and see an advertisement featuring American supermodel Amber Valletta, there will be some window of time during which the notions of coffee, bagel, and Amber Valletta will be on your mind. I’ve spent most of my life in New York City, so the probabilities of observing a coffee, or a bagel, are pretty high, meaning that neither item is likely to be the subject of a coincidence, at least as I’ve defined it above. Even if, e.g., someone throws a bagel at you, immediately after buying a bagel, you wouldn’t say it was a coincidence, because bagels are everywhere in New York, and as a result, it’s sensible to assume that someone just doesn’t like you, and threw a bagel at you, because you’re near a bagel store.
However, the probability of observing someone that looks like Amber Valletta is quite low, and that’s part of the reason she’s famous – she’s extremely good looking, and it is therefore, unlikely to observe someone that looks like her. So, returning to the example, if you had just purchased a coffee and a bagel, and saw an ad featuring Amber Valletta, and then suddenly, you see Amber Valletta walking down the street, wearing a t-shirt with an image of a coffee and a bagel on it, you’d be astonished, because the probability of seeing Amber Valletta is already extremely low, and the added conditional of a t-shirt featuring the items you just purchased brings the probability of the entire circumstance into the absurd.
This is a deliberately absurd example that highlights the nature of coincidence, which is the apparent transmission of information without causation. In this case, it seems as though Amber Valletta knew you would buy a coffee and bagel where and when you did, and knowing this, she purchased a t-shirt memorializing this information, and showed up to convey her understanding. That would probably be the impression generated by that set of facts, though it is of course possible that it just happened, without any deliberate action at all. As a practical matter, as the probability of the circumstance drops, and the intersection with your present expectation increases, you’ll become increasingly suspicious that it was in fact the result of deliberate action. To highlight this mechanic, imagine that your face was also featured on the t-shirt, so that the ultimate result is that you see Amber Valletta wearing a t-shirt with your face on it, and the items you just purchased, and are now holding in your hands. If that happened, you would probably refuse to believe that it was not deliberate.
Now, let’s be a bit more careful in addressing what’s happening: the most basic aspect of this set of facts is the occurrence of events that have extremely low probabilities. However, coincidence can be distinguished from the unexpected, in that coincidence has an additional element of relevance, where the events in question are not only extraordinarily unlikely, but also have something in common with your present set of expectations. In this case, the low probability event is seeing Amber Valletta, but the aspect that takes it from the merely unlikely, to coincidence, is the additional information memorialized on her t-shirt, which intersects with your present expectations. This is in contrast to, e.g., seeing a dead whale on Park Avenue, which is bizarre, but unless you just engaged in some whale-related activity, doesn’t rise to the level of coincidence, because it doesn’t intersect in property with your expectations.
When you think about coincidence in this manner, it highlights how truly strange it is, because the events in question must intersect with your expectations. But if the events intersect with your expectations, then how could they be low probability, since they’re already included in the aspects you’ve incorporated into your present expectations of the world? One solution, is to take those expectations, and paint a low probability event with some of them. So returning to the dead whale, imagine being a woman wearing a blue dress, and seeing a giant dead whale on Park Avenue with a similar, cleanly pressed, blue dress inexplicably draped over the whale’s head. This would take an already absurd scene, and paint it with the personal, since the event is not only extremely unlikely, but also conveys information that intersects with your present expectations. This thinking also highlights the psychological impact of coincidence, which is to take the familiar, and make it absurd, by associating it with an extremely unlikely event.
Note that the definition of coincidence I’ve defined above has two prongs, and therefore, two levers to pull in constructing a coincidence: one is the probability of the event, and the other is the scale of intersection with someone’s present expectations. We can, therefore, construct a pseudo-metric that measures the scale of coincidence itself, which (x) increases as the probability of the event decreases, and (y) increases as the intersection with someone’s expectations increases.
Returning to the example above, Amber Valletta is the low probability event, so that aspect of the hypothetical is essentially fixed. We can, however, adjust the scale of intersection, to increase the overall scale of coincidence. Imagine, for example, walking out of the bagel store, and seeing Amber Valletta wearing the exact same outfit as you, but for a large, ostentatious top hat, with a picture of your face on it, while holding a bagel and coffee. If this actually occurred, you would be justifiably convinced that this was deliberate, and that she somehow had access to information about you.
Coincidence as Indicative of Sentience
Before I get into the mathematics, I want to discuss what motivated this article in the first instance, which is the repeated and inexplicable coincidences I’ve noticed in the arts, and in my life generally. Again, I’m pushing the boundaries here on purpose, because the final result will be what I think is interesting mathematics that presents a totally new way of thinking about information and time. The fodder I’ll use to get there is admittedly a bit flimsy, since I’m calling upon coincidence to get the ball the rolling, but the end result will be real mathematics that models all the weird things I’ll describe.
My life has been pretty strange, to say the least, so there’s no shortage of examples, but the example I’ll lead with is a photo of a black hole that I downloaded to my phone sometime in September of 2017. I don’t know exactly what date I downloaded the picture, because the file itself is dated December 21, 2016, and as a result, the date displayed is the file date, not the date of download. However, it is between two other photos, one taken on September 11, 2017, at 1:49 PM, and another taken on September 29, 2017, at 10:27 AM. So, I must have downloaded the black hole picture sometime in between those two dates.
Here are the three photos, with the black hole photo in the middle:
The photo on the left is the first real break I had in physics, where I got very close to Einstein’s equations for time-dilation using information theory (here’s the end result of that work, where I rewrote all of special relativity and some of general relativity, using objective time: “A Computational Model of Time-Dilation“). The photo in the middle is of a black hole, that I suppose came from the internet, but I don’t remember what prompted me to download it, and the last image is a screen shot of an Andrew Bayer song that I’m guessing I liked, and didn’t want to forget, or perhaps I planned to send it to someone. Note that I’m not suggesting that I don’t like Andrew Bayer, because I do, I just don’t remember why I took the screenshot.
In sequence from left to right, what we have is a bunch of equations related to the nature of time, an image of a black hole, and a song that is apparently about memories from a prior existence. Now you can say I did this on purpose, which is fine, but I didn’t, but you don’t have to believe me, and it’s not relevant, because the point is, if you take the intersection over the set of ideas associated with the images, what you’ll end up with is fairly construed as a set of images related to the nature of time. I’m currently working on a paper and related software that actually models human association, meaning, and understanding in exactly this manner, by taking the intersection or union over associations, but for now, the point is, it’s fair to say that these three pictures together convey an impression about a topic that is related to the nature of time.
About two months later, on February 21, 2018, it was anomalously hot in New York City, reaching 79 degrees. This date, expressed using an American calendar, is 2/21, and removing the delimiter we have 221. Though presumably unrelated, the date of the black hole photo above is 12/21, and removing the delimiter we have 1221. This type of observation is justifiably dismissed as horribly unscientific, because there is no causal connection between a photo of a black hole, and an anomalously hot day a few months later. Expressed in terms of information theory, the date of the black hole photo provides no information whatsoever about the weather in New York City. But that misses the point, which is that if you want to a convey a message, you don’t need a causal relationship – all you need is a coincidence to get someone’s attention.
The point is not that the photo caused the hot day. The point is, that if the hot day was a signal, then one way to get the recipient’s attention would be to have some aspect of the hot day intersect in property with information from the recipient’s life. I’m obviously not saying that this is what happened, but rather, pointing out that conveying a message to a recipient that isn’t expecting a message can be done effectively using coincidence, the fruits of which are generally considered unscientific. So the net point is, not only is coincidence often the first step to a bona fide scientific insight, it’s also an incredibly useful way to get someone’s attention. This doesn’t mean you should run around looking for coincidences, but rather, the point is that there is real mathematics that we can develop around coincidence that allows us to discern between deliberate action, and the merely unlikely. That is, unpacking these types of fact patterns carefully allows you to develop mathematics that can measure the difference between a deliberate message, and a freak accident.
Returning to the example above, simply seeing Amber Valletta is unlikely, but not a coincidence. Seeing Amber Valletta dressed exactly like you, wearing a giant top hat with your face on it is a coincidence, the scale of which is so extreme, that it is almost certainly the result of deliberate action, and not the result of the undisturbed machinations of the universe. So, by considering an unfashionable topic carefully, we have developed rigorous mathematics that can distinguish between sentient action, and happenstance.
Finally, I’ll note that Amber Valletta’s initials are A.V., or 1.22., in the numerical order of the English alphabet, and yes, that’s why I selected her – it was in fact a coincidence, in this case, deliberate. I initially selected Charlize Theron, whose name intersects with mine, but I thought this was better for this particular purpose, since it requires converting a name to numbers, which I often do for fun. To make things a bit more bizarre, I’ll note that I was fortunate enough to have drinks on 2/21/2016 with a woman that has a strong resemblance to Amber Valletta, which I suppose you could say was a “hot date”.
Coincidence in the Arts
Because an artifact of the arts can generally be experienced at any given time, we’ll need to revisit the original definition of coincidence above, which requires only contextual relevance. That is, you can generally listen to a song whenever you’d like, so we want our notion of coincidence to cover those cases where the relevance doesn’t depend upon something that just happened. In the examples above, I used the notion of present expectations to determine the set of items that should be considered when determining the scale of intersection associated with an event. This is because considering the sum total of someone’s life will always generate some intersection with essentially every event, which muddles the analysis. As a result, I’ve deliberately limited the examples above to exogenous facts that intersect with someone’s recent, subjective experiences. But that might not always be appropriate.
For example, if a total stranger shows up to a bar you’re in, with your full, exact birthday written on their forehead, then whether or not you were thinking about your birthday, that experience obviously constitutes a coincidence, and would prompt a reasonable person to wonder exactly how that came to be. Similarly, if it is in fact your birthday, and a total stranger passes by with your full, exact birthday written on their forehead, this would, again, most certainly constitute a coincidence. The point is, however, that what is relevant is not always what is proximate in space or time, though what is proximate in space or time is, generally, fairly considered relevant, because that’s how people operate.
In contrast, if someone shows up to a bar with a bagel tattooed on their forehead, we might regard this as a curiosity, and certainly unlikely, but it does not satisfy the definition of coincidence above, because bagels do not intersect in relevance with the life of an ordinary person. If you work at a bagel store, or at a bagel company, then perhaps you could claim contextual relevance, but the point being, that for an ordinary person, in the ordinary course, bagels will not be contextually relevant, outside of proximate experience. As a result, this example highlights how we can objectively discern absolute, contextual relevance, outside of proximate experience, by considering only those items and ideas that are fairly considered unique to a given individual.
With this is mind, we can now evaluate coincidence in the mind of an observer of an artifact of art. Because I’m writing this article, the observer is going to be me, and because I think she’s a wonderful artist that is resetting American pop in the right direction, I’m going to discuss Halsey. It also turns out that there are a number of seriously bizarre coincidences between her work and mine, that will serve as excellent fact patterns for analysis.
To begin with, let’s consider the video for her song, “Graveyard”.
The first thing I’ll note is that the video is a time-lapse video, which is an expression of quantized time, which is a fundamental component of my research in physics. I think it’s fair to say that in the context of pop music videos, a time-lapse video is low probability, but of course, not entirely unheard of. Nonetheless, the point being, that to someone that spends a significant amount of time working on quantized time, seeing a pop video that makes use of quantized time garners attention.
At the time I listened to it, I remember thinking it was strange that she says, “let that sink in” at the 00:12 second mark, because I had just said the following on Twitter, a few days prior to the video’s release date:
I said that once, and I do have a superficial resemblance to classical representations of Satan, so, let that sink in …
This would constitute an intersection in relevance, because I just used the phrase a few days before listening to the song, but because it’s not a terribly uncommon phrase, I wouldn’t say that the two elements of coincidence outlined so far are compelling. But, it’s obviously enough to get your attention when you first hear a song that you enjoy. Also note that L is the 12th character in the English alphabet, and also the leading sound and letter of the phrase, “let that sink in”, which she says at the 12th second of the song. Further, the date of the black hole photo above is 12/21, which can be permuted slightly to form the sequence 1212, or “LL”, which, as I’ll explain below, is a variation on a moniker I’ve made only private use of, that basically no one knows about.
The next thing I noticed is a long, loud, conspicuous breath she takes at the 2:37 mark, which is simply not normal for a pop song. Ordinarily, pop artists go through considerable efforts, using noise gates and pop screens, to get rid of breathing sounds, but she decided to not only leave it in, but to also make a point of it, which is certainly low probability. It turns out, I did the exact same thing at the end of a song called, “Vega”, that I wrote one year ago, which was inspired by the story of Joan of Arc.
This is not something I would ordinarily do, since my background in audio production is mostly in pop and hip-hop, where you don’t want breathing noises, as a stylistic matter. But, I’m an independent artist, so I can do whatever I want. In contrast, Halsey is a commercial artist, that is making songs that need to sell, so her decision to break a norm is a commercial decision, which definitely caught me off guard, and I had trouble dismissing it, especially given the more subtle coincidences described above.
After listening to the song a few times, I noticed the subject of her painting, which includes a conspicuously, anomalously colored eye, and I realized that exactly one week prior to the release date of the video, I shared an image processing algorithm that produced the following image, when given a photo of myself that I took as input. The eye on the left is unnaturally dark, and the eye on the right is basically non-existent, none of which was deliberate – I simply applied the algorithm to the image, and this was the result. Moreover, even if I wanted to do this on purpose, I could not have known about the subject of the video, because it wasn’t released yet.
As a result of these coincidences, and the fact that I really liked her music, I decided to look into her music a bit more, and the weirdness just continued. It turns out that she wrote an absolutely beautiful song called, “Sorry”, explicitly about an “unknown lover”.
Five years ago, I also wrote a song explicitly about an “unknown” lover, which I haven’t thought about much since then. It was, regrettably, misinterpreted as a love song for the person I was dating at the time, despite what I thought were fairly explicit statements that the person in question is, “an unknown, in an unknown place”. But in any case, it is most certainly not about any particular person, and that was intended to be part of the charm of the song. Now, it is simply not the case that, eventually, every artist writes a song about an unknown lover. In fact, after a lifetime of playing, recording, writing, and listening to music, these are the only two examples of songs about unknown lovers that I’m aware of.
To be clear, these are not songs about secretly loving someone that is unaware of your affections, of which there are obviously plenty, since unrequited love is a classic topic. But rather, both of these songs are about love with respect to someone with an unknown identity – both of these songs are about missing information. To make things even more peculiar, Halsey suggests she has partial information about the person in question, saying that she knows the person’s birthday, and their mother’s favorite song, but otherwise knows nothing else about them. I wrote my song partly as a joke, as a clever way of saying that I’m not exactly married, which is a mean thing to do in retrospect, because I was dating someone at the time. In contrast, Halsey’s song is quite serious, and is saying explicitly that hers is a song about missing information, which is weird, considering that I’m an information theorist, that also happens to have a background in music production. Moreover, she’s saying in the song that she is in fact mean, and thoughtless, which is strange, because she seems quite nice, and I am certainly not nice, and certainly thoughtless, at least sometimes. Finally, her song was released on 2/2/2018, and “22”, read “deuce deuce“, is a really obscure moniker of mine, that only a few people know about, given to me by a guy whose name is also Charles, when I was 13 years old at summer camp, presumably so others could distinguish between us, though it is also a reference to a song called, “Hip Hop Ride“.
While I think I’m a handsome, brilliant man, I’m quite sure Halsey is not consciously writing love songs riddled with details from my life, as nice as that would be, or consciously conjuring my artistic concepts and bad personality traits. Rather, I think, either, this is the result of a ludicrously elaborate prank, or, in my opinion, more likely, real artists are truly weird people that might not operate the same way normal people do, which is a thesis I’ve repeated (see Section 4 of, “A New Model of Artificial Intelligence“), that, if true, could explain why creative people solve problems that appear to be superficially non-computable – musicians in particular. And while we’re on the subject of looks, though she is, thankfully for her sake, obviously far more attractive than I am, I’ll add that, after a simulated car accident, she looks a bit like I did around her age.
Handsome, brilliant math dude (2005).
But there’s more: she has a song called, “New Americana“, and I wrote a viola sonata called, “Song for a New America“. Again, these are not normal titles for songs, especially for a viola sonata.
And there’s still more: Halsey’s first actual photo on Instagram was posted on 5/6/19, which is my birthday, in the European calendar. You could say, “so what”, but Halsey’s first EP came out in 2014, and it’s a bit weird for a pop artist to start a social media account years into her career. The video for the song, “Ghost“, from her first EP, “Room 93“, was released on 6/11, which was my apartment number at the time, in Williamsburg, Brooklyn (i.e., my room number). And I’ll close with the observation that, the numerical string “93” translates into the alphanumeric string “ic”, which I interpreted as the product of i (the complex number), and c (the velocity of light in a vacuum). This is because I previously made the observation that, algebraically, our velocity in time is probably best thought of as the complex velocity, v = ic (see, footnote 7). When I first conceived of time as a complex number, I was living in Williamsburg, Brooklyn, and maybe two days after I originally conceived of the idea, a gigantic painting by an artist named Ron Agam was hanging in Whole Foods, called “Complex Universe”, that looked like a Frank Stella painting from the future. His last name is also “MAGA” backwards, which, I suppose, sucks for him.
So, do I think these coincidences rise to the level that indicates deliberate action? Not really, generally speaking, but sometimes I do, because they’re an effective way of identifying someone working on stuff you’d prefer they didn’t – just imagine using A.I. to not only make all these observations, but also plow through social media and other data to find the people that check all the boxes. This will give you a short list. But they are, in any case, super weird coincidences, whether or not Amazon or someone is paying Halsey to ID the dude doing the math stuff that might make their whole server business thingy go broke, and model consumer preferences more efficiently, which, I guess, they probably wouldn’t like either.
I don’t think she is doing this, but the point is, it’s possible, and that’s not good news.
But, back to science, in the next article, I’ll present an admittedly theoretical mathematical model of how information could be exchanged through time, that would, if true, explain all of this in a manner that doesn’t require malicious intent, but nonetheless allow for causation and the ordinary progression of the laws of physics to generally persist as usual.
So, do I think artists actually make use of these processes, exchanging information through time? Yes, and I know that makes me sound crazy, but I don’t care, because I’m right about so many things in science, particularly A.I., which is testable on a laptop anywhere in the world, that I’m not worried about my reputation anymore. I think that just as ordinary light bounces off a mirror, there’s another type of momentum that can be exchanged through time, allowing for information to bounce back from likely futures. I think gravity is an example of this (see, my rant on Twitter).
I think this is how mathematicians and some artists solve non-computable problems – by having access to information that most people don’t. Separately, I also think intelligence is quantized, but not like an IQ test, but rather, like the jump from one infinite cardinal to the next. And I think IQ measures deductive problem solving, which has declining marginal utility, which is why people that score in the top 1% to 5% on standardized tests are just as intelligent as people that have a freakishly high IQ. In contrast, I think creative people are producers of new information, which cannot be the product of deduction (see Section 4 of, “A New Model of Artificial Intelligence“), so you can’t measure that by asking questions that have deductive answers. You can only look at the volume, and complexity, of original output produced by the person in question. So as a practical example, Mozart would probably do just fine on an IQ test, but that’s not why he’s a genius – he’s a genius because he wrote so much complex music, it’s hard to believe he did anything else: by the time he was nine years old, he had already written five symphonies. You can’t test for that, other than to ask a kid to write five symphonies, which you’ll just have to wait for.
I’ve written another arrangement of the song I posted below, “Jane” and significantly improved the audio production, and now, despite the fact that it was recorded on an iPhone, it sounds really good, and honestly, after a lifetime in audio production, I’ve heard far worse come out of real studios. So, you too can produce real music with editing software, some sound libraries, an A/D converter, good headphones, and an iPhone. These are the particular products I used, but the point being, that with a few hundred dollars, and an iPhone, you can set yourself up to record top quality music. But the real reason I’m writing about this is because I’ve been thinking a lot about Dada art, and while I’ve always been a fan, since I’ve started my work in A.I., my interest in the genre has increased significantly, as I find kicking ideas around using Dada art incredibly useful, because Dada artists consciously pushed every boundary, which puts any ideas you have on the formalization of art to the ultimate, and most ridiculous test.
In this piece, I took a song that I deliberately wrote to be about love between two human beings, but then changed the context of the song using an icon as representative of the piece – the portrait of Joan of Arc below. This changes the context of the song, suggesting a love between humanity and God. The topic of religious love is beyond unfashionable, and I can imagine many people simply saying, “no thanks”. Moreover, an art-school style discussion of the topic is basically an anathema to the contemporary art scene. Using Dada art to express religious intution is a party of one (at most two, and if you’re out there, send me an email), in terms of producers of this type of product, but I’m fine with that outcome, as I think plenty of intellectuals have religious intuitions, and so there’s almost certainly unsatisfied demand for interesting, technically-minded religious art.
I do these things on purpose, because I want to trick people into thinking about the nature of reality, and the possibility of God, so I’ll write a song that sounds like an ordinary folk love song, and then completely change the context of the message with the addition of a religious symbol that is associated with the song. The goal being that you like the song, and are therefore tricked into considering the nature of something that I believe to be important, and too often dismissed, simply as a result of pretensions, or perhaps something more sinister, like the persecution of religiously minded people.
In this case, in this version, I’ve made the reference to God explicit during the final chorus, using a bit of repurposed, Dada poetry by Agnes Ernst Meyer, used as a spoken word overlay to the final chorus. The spoken word track is deliberately gutted in terms of EQ, leaving a tinny sound, that is hard-panned to the left. The net effect is that you hear the talking, but because it’s mostly limited to the left channel, and very tinny in terms of timbre, you’ll probably generally disregard the actual substance of the words, focusing instead on the rest of the music and the main lyrics. It’s almost like an unimportant subway announcement made in the midst of listening to a song that you’re trying to enjoy, which will change the sound of your environment, but without conscious attention, won’t change the message.
However, if you do listen to the text, it does change the message, and the manner in which it changes the message is arguably subjective, because the text is lifted without change, from a context that’s not a perfect fit for the song. This act, of taking a thing, and changing the context of the thing, by adding or removing information, is arguably a foundational tool of Dada art. Personally, I think a change in context in music is the most interesting, and intellectually challenging device a musician can make use of, as taking a melody, and placing it in a new context, or a new key signature, is, as a technical matter, extremely difficult, providing the listener with much to consider, as the familiar becomes the novel, requiring re-evaluation.
Marcel Duchamp was a ridiculous human being that did something like this in visual art, without shame, and without regard for the history of art, or arguably, civilization itself. Drawing a mustache on Mona Lisa could be dismissed as vandalism, and maybe that’s the right conclusion in that case, but the tool he brutally highlighted is the ability to change the context of a message by adding or removing information from the message.
The song itself, with just acoustic guitar and voice, is very beautiful, but the addition of flute, viola, and spoken word overlay in the last chorus transforms the piece from a simple folk song, to something unusual, which pulls the listener in, because the additional information forces you to think and engage. If you want to understand the piece, now you’ll have to pay attention to the tinny spoken word in the left speaker, which means you’ll probably have to listen to the piece a few times. This will in turn cause you to become better associated with the song, and probably, leave the melody stuck in your head as a result. So in addition to changing the sound of the piece, and providing new harmonic information to consider, the addition of the new elements changes the way the listener engages with the piece, thereby creating a fundamentally different piece of art.
The addition of the explicit reference to God, in the song itself, suggests, that perhaps there is a connection between understanding love, and God, since I claim to understand what love is, in the context of a song that would otherwise probably be interpreted as a love song about two human beings. In the context of modern pop music, this is definitely going to push some boundaries in the mind of the listener, since at the very end of an otherwise normal folk song, the listener is confronted with a collage of information that completely changes the context of the song, from an ordinary love song, to something unusual, that is possibly about God’s love.
I don’t say the word God, and instead say the word “odd”, simply because the text is lifted mostly as is, from the original text, but my intent was to evoke the word “God” in the mind of the listener. This is itself a game of signal and response, where my pronunciation, and the context of the message, changes the response triggered by the literal text of the message. In this case, it is the result of working with what you have, though it is clearly evocative of religious prohibitions on expressions related to God. Some religions don’t write down the actual name of God, others have prohibitions on creating images of God, and I’ll admit, several times in my work in mathematics and physics, I stopped what I was working on, because I thought I was pushing the boundaries of what human beings should know. Once I did it explicitly for personal, religious reasons, but usually I stop because I don’t trust human beings – as a practical matter, I don’t think we’re supposed to know all the things, given our performance thus far, with only some of the things.
So the idea of prohibitions on expressions related to God is fundamental to many religions, yet censorship is obviously in some sense an enemy of art. This places art in a difficult position with respect to religion, which is nothing new, and clearly why religious institutions generally seek to control the arts. At the same time, art is a great way to express your understanding of God, and God is, therefore, a frequent subject in classical art, before we surrendered ourselves to unmitigated commercialism. Unconventional religious art is likely to be poorly received by both religious institutions and deliberately atheist movements, like communism, because not only does it challenge conventional religious beliefs, it could also be used to inspire moral considerations beyond the laws of the state, which is effectively god for communists. So, by implication, with the mere suggestion of the idea of God, a flute, and a viola, we can turn an ordinary folk song into a philosophically, economically, and politically loaded work of art.
As an American, I refuse to be censored in terms of legal restrictions, but I do try to be respectful of religion, because I understand the nature of deeply held beliefs, that define how people see themselves, and the world. And I understand how important this is to people. But I understand, because it’s also important to me, and I think the bargain that we struck in America is the correct one:
You can say, and think, whatever you want about God, as a legal matter, but you have to tolerate whatever I say, and think about God, as a legal matter. This forces us to behave like adults, and understand that the world is a heterogeneous place, not only with respect to humanity, and ideas, but in general – just look around, you’re not going to find one thing at our level of existence, as this is a place of remarkable multiplicity and diversity.
And just like we don’t all speak the same language, we likely suffer from an inability to describe God in the same terms. As for myself, I can’t convey my notion of God using text on a page, because that’s not how I understand God. That doesn’t mean we have different gods, it just means I don’t speak your language. For me, describing God requires something different – I need to show you what I think, you need to hear it, and I need to write down some equations that describe how things move in space and in time, and then, and even then, I’m still not done, because I don’t believe that I can fully understand what God is, so I can’t completely describe God to you, but I’m certain I understand what love is, and I hope I’ve painted a decent portrait of my understanding with this song.
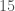
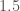

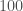
 states can be used to represent
states can be used to represent  binary bits. The same is true of a shoe box – either the lid is on, or it isn’t, and as a result, a shoe box is a physical system that has two states, and can store
binary bits. The same is true of a shoe box – either the lid is on, or it isn’t, and as a result, a shoe box is a physical system that has two states, and can store 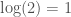 bit of information. This is not how normal people think about the world, but it is how an
bit of information. This is not how normal people think about the world, but it is how an  that is the minimum segment size into which you can divide any length. As a result, when presented with a line of length
that is the minimum segment size into which you can divide any length. As a result, when presented with a line of length  , the maximum number of possible discernible locations along its length upon which you could place an object is given by,
, the maximum number of possible discernible locations along its length upon which you could place an object is given by,
 that you can place upon any given line, and as a result, the maximum number of states that can be generated by placing objects upon any given line is
that you can place upon any given line, and as a result, the maximum number of states that can be generated by placing objects upon any given line is  . Therefore, the information capacity of a system comprised of
. Therefore, the information capacity of a system comprised of 
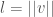 using
using  bits. For example, if we want to express a vector in two-space, we need to specify only the length of the vector, which requires
bits. For example, if we want to express a vector in two-space, we need to specify only the length of the vector, which requires 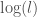 bits, and the angle the vector forms with either the horizontal or vertical axis. Because the angle does not change as a function of the norm of the vector, it requires a constant amount of information to represent, resulting in a total number of bits given by
bits, and the angle the vector forms with either the horizontal or vertical axis. Because the angle does not change as a function of the norm of the vector, it requires a constant amount of information to represent, resulting in a total number of bits given by  , will be associated with an amount of information given by,
, will be associated with an amount of information given by,
 . Now let’s suppose we are told by a third party that the level of luminosity is hypothesized to be
. Now let’s suppose we are told by a third party that the level of luminosity is hypothesized to be  . The error in this case is given by,
. The error in this case is given by,
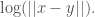 The net information of the hypothesis is given by,
The net information of the hypothesis is given by, .
.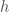 in part because capital
in part because capital  is associated with information through Shannon’s equation for entropy. This equation allows us to distinguish between exact, imprecise, and incorrect answers, since
is associated with information through Shannon’s equation for entropy. This equation allows us to distinguish between exact, imprecise, and incorrect answers, since  , less than
, less than  but positive, or negative. As a simple example, the following is Octave code that takes a given observed luminosity as input, and iterates through increasing hypothetical luminosities from
but positive, or negative. As a simple example, the following is Octave code that takes a given observed luminosity as input, and iterates through increasing hypothetical luminosities from 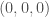 , until it produces an incorrect hypothesis, using the criteria above.
, until it produces an incorrect hypothesis, using the criteria above. will be mapped to some association cluster
will be mapped to some association cluster  , where each
, where each 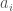 is an integer that corresponds to some bundle of sensory information in the dictionary, each of which is really just a memory. As a practical matter, the dictionary would be modeled on the sender-side by an integer-indexed table of pointers that reference what could be various forms of media, including images, sounds, words, etc. This means that an entry in the dictionary would point to something similar to what the recipient actually conjures upon observing the signal. So, for example, if I show you an orange, my model of your associations would probably include photos from your social media accounts that are related to oranges. This is actually astonishing when you think about it, because it means that companies can literally look into your actual mental associations, which probably include photos from your social media libraries –
is an integer that corresponds to some bundle of sensory information in the dictionary, each of which is really just a memory. As a practical matter, the dictionary would be modeled on the sender-side by an integer-indexed table of pointers that reference what could be various forms of media, including images, sounds, words, etc. This means that an entry in the dictionary would point to something similar to what the recipient actually conjures upon observing the signal. So, for example, if I show you an orange, my model of your associations would probably include photos from your social media accounts that are related to oranges. This is actually astonishing when you think about it, because it means that companies can literally look into your actual mental associations, which probably include photos from your social media libraries –  . For simplicity, we’re going to assume that the signals are not context dependent, and are not sensitive to order. That is, the associations triggered by
. For simplicity, we’re going to assume that the signals are not context dependent, and are not sensitive to order. That is, the associations triggered by  are always the same, regardless of whether I deliver that signal alone, or in the context of a larger set of signals. This is not how most human languages work, since language is generally sensitive to context. Instead, what I’m going to define are two primal, symbolic languages, one rooted in the intersection operator, and the other rooted in the union operator. These will ultimately produce something like context, but the point is that the associations generated by the individual signals are not sensitive to context, whereas the overall meaning of the signal will be sensitive to the total set of signals delivered.
are always the same, regardless of whether I deliver that signal alone, or in the context of a larger set of signals. This is not how most human languages work, since language is generally sensitive to context. Instead, what I’m going to define are two primal, symbolic languages, one rooted in the intersection operator, and the other rooted in the union operator. These will ultimately produce something like context, but the point is that the associations generated by the individual signals are not sensitive to context, whereas the overall meaning of the signal will be sensitive to the total set of signals delivered. over the language of intersections is,
over the language of intersections is,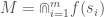 ,
,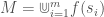 .
.
 , and taking iterative intersections over the sets
, and taking iterative intersections over the sets  and
and 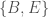 , which will eventually leave you with the singleton
, which will eventually leave you with the singleton  . This can be modeled with software, if you know what ideas your recipient associates with a given signal, which would allow you to deliver a sufficient number of signals to make it clear to your recipient that you are painting the event with their colors, and not someone else’s. This in turn allows you to encrypt the core identifying signal itself, since rather than simply present a picture of the particular one-eyed cat, you can instead reference the cat through disaggregated association, if you know how your recipient makes associations between signals and ideas.
. This can be modeled with software, if you know what ideas your recipient associates with a given signal, which would allow you to deliver a sufficient number of signals to make it clear to your recipient that you are painting the event with their colors, and not someone else’s. This in turn allows you to encrypt the core identifying signal itself, since rather than simply present a picture of the particular one-eyed cat, you can instead reference the cat through disaggregated association, if you know how your recipient makes associations between signals and ideas.





