I’ve applied my knowledge-based prediction algorithm to the UCI Credit Dataset (which I’ve attached, already formatted), and the results are the same as always, peaking near 100% accuracy (using only 3,500 rows). What’s interesting is the use of ordinal values, in this case levels of education. Though I didn’t explicitly do it in this case, what you could do is simply use my normalization algorithm as applied to those dimensions that contain ordinal values. This will cause the normalization algorithm to use different orders of magnitude for the ordinal dimensions, thereby solving for the appropriate spacing between ordinal values. So for example, if the possible ordinal rankings are (1, 2, 3), then this application of the normalization algorithm will test, e.g., (10, 20, 30), (100, 200, 300), etc., each of which will produce different accuracies, with the best one selected.
Below is a plot of accuracy as a function of knowledge, which you can read about in the first paper linked to above:

Note that this will not work for truly arbitrary labelled data, where the values have no obvious numerical meaning (e.g., colors). In that case, you could iterate through different ordinal rankings of the labels (i.e., permutations), and then use the normalization method to solve for the best numerical values for the labels for each ordinal ranking. Nonetheless, attached is command line code that both normalizes and runs predictions on the UCI Credit Dataset. This is going to be included in some commercial release of my software, but given that it’s so powerful, I’m probably not going to release it on the Apple App Store as part of my Kickstarter Campaign (at least not this version of it).
 .
.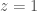 , and you have the sum in question, which is plainly
, and you have the sum in question, which is plainly  be the set produced by the union of disjoint sets of sizes
be the set produced by the union of disjoint sets of sizes  , where
, where 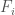 is the i-th Fibonacci number. It must be the case that
is the i-th Fibonacci number. It must be the case that  . More troubling, addition between integers can be put into a one-to-one correspondence between unions over disjoint sets, and thus, we have an apparent paradox.
. More troubling, addition between integers can be put into a one-to-one correspondence between unions over disjoint sets, and thus, we have an apparent paradox. . If you sum from left to right, you can cause the sum to oscillate near any finite value, or to diverge to positive or negative infinity, without changing the terms at all, simply changing their order. So as a consequence, it must be the case that the rules of algebra require reconsideration in the context of an infinite number of terms. I’m not suggesting that this is what’s driving the apparent paradox above, but rather pointing to the general issue that mechanical application of the rules of algebra to an infinite number of terms is not appropriate, and this example plainly demonstrates that fact.
. If you sum from left to right, you can cause the sum to oscillate near any finite value, or to diverge to positive or negative infinity, without changing the terms at all, simply changing their order. So as a consequence, it must be the case that the rules of algebra require reconsideration in the context of an infinite number of terms. I’m not suggesting that this is what’s driving the apparent paradox above, but rather pointing to the general issue that mechanical application of the rules of algebra to an infinite number of terms is not appropriate, and this example plainly demonstrates that fact. , and the numbers -1 to -100, in vector
, and the numbers -1 to -100, in vector  , listed in descending order. This would produce the following plot in the
, listed in descending order. This would produce the following plot in the 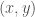 plane:
plane:
 , and for vector
, and for vector  , where
, where  is the number of items in each vector. Therefore, by taking the difference between the corresponding ordinals in
is the number of items in each vector. Therefore, by taking the difference between the corresponding ordinals in 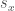 and
and 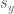 , we can arrive at a measure of correlation, since it tells us to what extent the values in
, we can arrive at a measure of correlation, since it tells us to what extent the values in ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) scale, and the results are exactly what intuition suggests, which is that the example above constitutes perfect negative correlation, an increasing line constitutes perfect positive correlation, and adding noise, or changing the shape, diminishes correlation.
scale, and the results are exactly what intuition suggests, which is that the example above constitutes perfect negative correlation, an increasing line constitutes perfect positive correlation, and adding noise, or changing the shape, diminishes correlation.