My AutoML software, Black Tree AutoML, can already predict credit outcomes with no specialization at all. But it just dawned on me that with a bit of work, you can use any clustering and classification system to model credit in a meaningful way. First let’s define the relevant properties of a credit, which are its assets, and its liabilities, and for simplicity, we’ll include the equity capital of the credit in its liabilities. This will allow us to express a credit, at a given moment in time  , as a vector
, as a vector 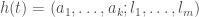 , where each
, where each 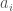 is the value of assets of type
is the value of assets of type  owned by the credit, and each
owned by the credit, and each  is the value of liabilities of type owed by the credit. Because this is so abstract, this allows you to consider not only corporates, but SPV’s as well, and individuals.
is the value of liabilities of type owed by the credit. Because this is so abstract, this allows you to consider not only corporates, but SPV’s as well, and individuals.
Now let’s posit a dataset of credits 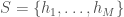 , that were sampled over time. That is,
, that were sampled over time. That is, 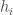 is actually a time-series of a given credit, and we can evaluate
is actually a time-series of a given credit, and we can evaluate  , for any within some ordinal interval, though you could also consider specific periods of time as well. The overall gist being, we have observed and recorded the state of a given credit over time, in the form of the vector . We can therefore, pull all credits that are sufficiently similar to some new input credit
, for any within some ordinal interval, though you could also consider specific periods of time as well. The overall gist being, we have observed and recorded the state of a given credit over time, in the form of the vector . We can therefore, pull all credits that are sufficiently similar to some new input credit 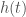 , which will produce a cluster of similar credits. Because our dataset contains time-series data for each of the credits returned in the cluster, we can form possible future paths for . This will allow us to say, as a general matter, what the future of
, which will produce a cluster of similar credits. Because our dataset contains time-series data for each of the credits returned in the cluster, we can form possible future paths for . This will allow us to say, as a general matter, what the future of 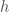 will look like, given its present state . Moreover, we can easily construct a probability of default, again using the cluster, since all of the credits in the cluster either paid or didn’t, though you could have some unknowns as well as a practical matter (i.e., those credits are still outstanding).
will look like, given its present state . Moreover, we can easily construct a probability of default, again using the cluster, since all of the credits in the cluster either paid or didn’t, though you could have some unknowns as well as a practical matter (i.e., those credits are still outstanding).
Applying this process repeatedly to the initial state of some credit  , we will construct a set of possible future paths for , given that initial state. Specifically, first we find the cluster associated with . Then, we find the next state for each credit in that cluster. So, e.g., if credit
, we will construct a set of possible future paths for , given that initial state. Specifically, first we find the cluster associated with . Then, we find the next state for each credit in that cluster. So, e.g., if credit 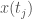 is in the cluster associated with , we find the next state of in the cluster, which we can represent as
is in the cluster associated with , we find the next state of in the cluster, which we can represent as  . We do this again, for all such
. We do this again, for all such  , and continue as desired, and this will produce a dataset of possible future paths for the credit, which will grow exponentially as a function of time, and at each ordinal interval of time, there will be some probability of default based upon the dataset.
, and continue as desired, and this will produce a dataset of possible future paths for the credit, which will grow exponentially as a function of time, and at each ordinal interval of time, there will be some probability of default based upon the dataset.
My AutoML software is typically really accurate, so I would wager that if you use my software for the clustering step, you’re going to get great answers, and probably make a lot of money as a consequence, and so it’s another great reason to buy my software, which is comically better than everyone else’s.
