I’ve got another batch of algorithms coming out soon, so I thought I’d get some more work done on my new book first:
Enjoy!
I’ve put together a brief summary of my most recent work in vectorized deep learning, and uploaded an updated zip file of my algorithms.
Enjoy!
The ZIP file is available on my ResearchGate Homepage.
I was thinking about one-off states of systems, since these are arguably bad for predictions –
Just imagine assuming that a new state is similar to some known one-off state, because they are for example nearest neighbors in the space of the dataset. It could very well be the case that the dataset is simply not consistent around the known one-off state, and that’s why it was clustered alone.
This in turn led me to think about the possibility of one-off states of physical systems, which ultimately led me to the following idea:
Take a discrete integer-labeled subset of Euclidean space, and draw a point at a given index 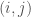

where 
![[0,255]](https://s0.wp.com/latex.php?latex=%5B0%2C255%5D&bg=ffffff&fg=444444&s=0&c=20201002)

Below are the first 50 solutions, beginning with 


















































Because
This was actually part of my thought process, since electron orbitals are wildly different shapes as a function of energy.
I thought this was interesting, since the allure of automata is that they produce patterns that don’t have obvious closed-form equations. These patterns however don’t appear to be the product of a closed-form equation, but they are, and it’s a simple one at that. Moreover, they get really aesthetically interesting for larger values of
Here are some examples for 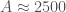









You can of course express a three-dimensional analog, and this was the original idea, but I really like the way the two-dimensional version looks:

The code for both the two-dimensional and three-dimensional version is attached.
Imagine you’ve got a vector of integers, ![v = [1 2 3 4 5]](https://s0.wp.com/latex.php?latex=v+%3D+%5B1+2+3+4+5%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![[3 2 5 4]](https://s0.wp.com/latex.php?latex=%5B3+2+5+4%5D&bg=ffffff&fg=444444&s=0&c=20201002)


But now imagine instead we permute the original vector 
![[3 4 2 1 5]](https://s0.wp.com/latex.php?latex=%5B3+4+2+1+5%5D&bg=ffffff&fg=444444&s=0&c=20201002)
If we keep doing this, we can generate up to 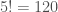
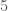
This suggests a question:
Is there a difference between doing exactly that, and tolling the random variable 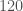
The answer is, yes, and it’s easily measurable.
For the string generated by permutation, the average over every sequence of length five is exactly 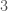
Take the average over the entire string, and then iterate through cycle lengths, taking the average over each resultant cycle, until every cycle average equals the overall average.
So in our example above, we would iterate through cycle lengths, beginning at 
For a much larger set of numbers, you can have an enormous number of permutations, until you necessarily have repetition. For example, if 

A lot of people have considered the issue of superficial randomness, and I’m certainly not the first person to do so, though what I’m really interested in is –
Whether or not we should find random variables in nature, if physics computable.
My answer is, I’m not sure.
It’s obvious that basic physics is computable, and this has some consequences that are unavoidable, as a matter of pure math.
For example, despite what people say about physical entropy increasing over time, a computable process of nature simply cannot increase beyond a bounded rate of Kolmogorov complexity over time. Specifically, if 

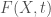

This can be specified with 
I.e., the sum over the complexities of the initial conditions, the rule of the system, and the amount of time elapsed. 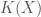



This is simply the way it is, and there’s no debating this, and it implies that the complexity of a computable system is bounded over time.
There is some room to disagree about what constitutes a random variable, but my personal view is that a random variable should produce Kolmogorov-random observations. Assuming otherwise implies that there are computable patterns in the resultant data.
You could allow for this, but is it really random, if a machine can compress the output? In the extreme case, allowing for non-Kolmogorov-random, random variables, would allow for obvious symmetries in observations generated by a random variable, and that just doesn’t satisfy intuition.
For that reason, I’m going to assume that observing a random variable for a sufficiently long time will generate a Kolmogorov-random string.
So in this view, where could physically real, Kolmogorov-random objects come from, if the rules of physics are computable?
I think one answer is exhaustive processes, that generate all possible outcomes over a range. This a computable way of generating random outcomes:
Simply generate every possible outcome in a range, and some of them will be Kolmogorov-random.
This is a strange consequence of computing, in that it’s easy to generate all strings of a given length, many of which will be Kolmogorov-random, but generating a particular Kolmogorov-random string cannot be done, without an input that is at least as long as the output. Physically, this means that you can’t produce a Kolmogorov-random object using a computable rule of physics, unless you start with an object of equivalent or larger size.
I can’t point to anything that actually generates all objects in a possible range of, e.g., energies, and so I am instead pointing out that even with computable physics, you can still generate Kolmogorov-random objects, though you can’t generate exactly one without starting with a larger object.
This allows for two possibilities:
1. You have a process that generates all possible objects in a given range of sizes, many of which will be Kolmogorov-random;
2. You have a process that starts with a massive object, and winnows it down to a smaller Kolmogorov-random object.
Over enough time, you could at least conceive of an object that is Kolmogorov-random, generated as part of some massive process, that gets separated from its source, and appears as a single, inexplicable object, but I can’t think of any examples, and I’m instead simply working through the underlying mathematics of what’s possible with computable physics.
I also spend a lot of time thinking about the complexity of life, and what you find there is very similar to what you find in art –
Highly complex components, and a symmetric overall structure.
For example, the structures of a bird, butterfly, or human face, are all highly symmetrical, but extremely complex in their individual components. To make the analogy to computer theory, it’s similar to starting with a Kolmogorov-random string, and performing basic operations on that string, such as reading it backwards, or perhaps subdividing it, and repeating some of its components. This would generate an overall string that could be significantly compressible, that nonetheless consists of individual components that are in isolation, Kolmogorov-random.
So even with all of this said, the arguments above point only to the possibility of Kolmogorov-random objects, which are distinct from systems that generate truly random observations.
