This is still a work in progress, but it contains a lot of functions that I found to be missing from Swift for doing machine learning, and using matrices in general.
Note this is of course subject to my copyright policy, and cannot be used for commercial purposes.
The actual commercial version of my core A.I. library should be ready in about a month, as this is going much faster than I thought it would.
I’ve also included a basic main file that shows you how to read a dataset, run nearest neighbor, manipulate vectors, and generate clusters. It’s the same exact algorithms you’ll find in my Octave library, the only difference being it’s written in Swift, which is not vectorized, but has the advantage of publishing to the Apple Store, and that’s the only reason I’m doing this, since I don’t really need a GUI for this audience.
My core work in deep learning makes use of a notion that I call , which is the minimum distance over which distinction between two vectors is justified by the context of the dataset. As a consequence, if you know , then by retrieving all vectors in the dataset for which , you can thereby generate a cluster associated with the vector . This has remarkable accuracy, and the runtime is , where is the number of rows in the dataset, on a parallel machine. You can read a summary of the approach and the results as applied to benchmark UCI and MNIST datasets in my article, “Vectorized Deep Learning“.
Though the runtime is already fast, often fractions of a second for a dataset with a few hundred rows, you can eliminate the training step embedded in this process, by simply estimating the value of using a function of the standard deviation. Because you’re estimating the value of , the cluster returned could very well contain vectors from other classes, but this is fine, because you can then use the distribution of classes in the cluster to assign a probability to resultant predictions. For example, if you query a cluster for a vector , and get a cluster , and the mode class (i.e., the most frequent), has a density of within , then you can reasonably say that the probability your answer is correct is . This turns out to not work all the time, and very well sometimes, depending upon the dataset. It must work where the distribution of classes about a point is the same in the training and testing datasets, and this follows trivially from the lemmas and corollaries I present in my article, “Analyzing Dataset Consistency“. But of course, in the real world, these assumptions might not hold perfectly, which causes performance to suffer.
Another layer of analysis you can apply that allows you to measure the confidence in a given probability makes use of my work in information theory, and in particular, the equation,
,
where is the total information that can be known about a system, is your Knowledge with the respect to the system, and is your Uncertainty with respect to the system. In this case, the equation reduces to the following:
,
where is the size of the prediction cluster, is the number of classes in the dataset, is again Knowledge, and is the Shannon Entropy of the prediction cluster, as a function of the distribution of classes in the cluster.
You can then require both the probability of a prediction, and your Knowledge in that probability, to exceed a given threshold in order to accept the prediction as valid.
If you do this, it works quite well, and below is a plot of accuracy as a function of a threshold for both the probability and Knowledge, with Knowledge adjusted to an scale, given rows of the MNIST Fashion Dataset. The effect of this is to require an increasingly high probability, and increasing confidence in your measure of that probability. The dataset is then broken into random training and random testing rows, done times. The accuracy shown below is the average over each of the runs, as a function of the minimum threshold, which is again, applied to both the accuracy and the confidence. The reason the prediction drops to at a certain point, is because there are no rows left that satisfy the threshold. The accuracy peaks at , and again, this is without any training step, so it is in fairness, an unsupervised algorithm.
This method is already baked into some of my most recent posts, but I wanted to call attention to it in isolation, because it is interesting and useful. Specifically, my algorithms are generally rooted in a handful of lemmas and corollaries that I introduced, that prove, that the nearest neighbor method produces perfect accuracy, when classifications don’t change over small fixed distances. That is, if I’m given a row vector from the dataset, and the set of points near have the same classifier as , then the nearest neighbor algorithm can be modified slightly to produce perfect accuracy. And I’ve introduced a ton of software that allows you to find that appropriate distance, which I call . The reason this sort of new approach (I came up with this a while ago) is interesting, is because it doesn’t require any supervision –
It uses a fixed form formula to calculate , as opposed to a training step.
This results in a prediction algorithm that has runtime, and the accuracy is consistently better than nearest neighbor. Note that you can also construct an runtime algorithm using the code attached to my paper Sorting, Information, and Recursion.
Here are the results as applied to the MNIST Fashion Dataset using 7,500 randomly selected rows, run 500 times, on 500 randomly selected training / testing datasets:
1. Nearest Neighbor:
Accuracy: 87.805% (on average)
2. Cluster-Based:
Accuracy: 93.188% (on average)
Given 500 randomly selected training / testing datasets, the cluster-based method beat the accuracy of nearest neighbor method 464 times, the nearest neighbor method beat the cluster-based method 0 times, and they were equal 36 times. The runtime from start to finish is a few seconds (for a single round of predictions), including preprocessing the images, running on an iMac.
NOTE: there is an error in the code, that I am deliberately leaving, because I can’t explain why accuracy actually increases as the code is written, as a function of confidence. I’m working on something else at the moment, post coming soon, but I wanted to flag the error, and the related apparent mystery. In short, the code as written returns the cluster for a random row of the dataset, rather than the row that the input vector mapped to.
Attached is code that implements information-based measures of confidence, that allows you to filter predictions based upon confidence, in turn improving accuracy. Below are two images, one showing the total number of errors for each class of the dataset as a function of confidence (on the left), and another showing overall accuracy as a function of confidence (on the right), each as applied to the Harvard Skin Cancer Dataset, which I’ve found to be awful, as the images are not consistent, and one class makes up basically all of the data.
In each case, prediction was run 1,000 times, using 1,000 randomly generated training and testing datasets, comprised of 350 rows, which is a very small subset of the roughly 10,000 rows of the dataset. This is why the number of errors begins in the thousands, because it is the total over all runs (bottom image). In contrast, the accuracy is the average accuracy at a given level of confidence (x-axis) over all runs (top image). The purpose of this initial note is to demonstrate that the measure of confidence works, and later, I will run the same simulation on the full dataset, to demonstrate that not only does the measure of confidence work, but it also works in solving practical datasets, increasing accuracy. In any case, because it was a such a challenging dataset, it lead to this implementation, which was ultimately a good thing.
The fundamental principle underlying the measure of confidence, is the equation I introduced a while back, which is , where is information, is knowledge, and is uncertainty. In this case, confidence in a prediction is given by . I’ll explain how those values are calculated later, but you can look through the code to see they’re related to entropy and information theory generally. The equation states something that must be true about epistemology, which is that the sum of what you know about a system (), and what you don’t know about the system(), must be the sum total of information regarding the system (). What’s interesting in this application, is that using information theory and combinatorics, we can actually solve for all three variables, and empirically, it works, at least in the case of this dataset. I don’t think you can ever prove that you’ve used the correct values for these variables, but you can use information theory to derive objective values for all three variable.
Original Dataset Size: 7470 RGB images of various dimensions;
Compressed Dataset Size: 7470 x 198;
Preprocessing time: 37.9 seconds;
Supervision Training time: 55.9 seconds;
Prediction time: 13 seconds, on average (run 25 times);
Prediction accuracy:
Worst case, 85.542% (no supervision);
Best case, 95.8337% (highest level supervision, rejecting all but 62 rows).
Bottom line: Reliable diagnosis for over 7,000 patients, on a home computer, in about 2 minutes.
Summary of Process
The dataset consists of just over 10,000 images of legions. Each legion belongs to one of seven classes of legions, three of which are malignant. The algorithm consolidates all malignant classes into one, and consolidates all benign classes into one. It removes all duplicate images, leaving only one image per patient. All images are then compressed, and fed to a supervised algorithm that finds the minimum and maximum distances over which classification labels are consistent within the dataset. Then prediction is applied using decreasingly sensitive criteria for flagging predictions as outside the scope of the training dataset.
I’ve also attached a “STAT SUPERVISION” script that can be applied without consolidating classes, and generates about 80% accuracy (also using rejections). This is the same algorithm I introduced in Section 1.4 of this paper, for the “Statistical Spheres” dataset, the only difference here is the clusters don’t have the same classifier, but the algorithm is exactly the same.
There’s another method called “Isolate Classes”, the code for which is also attached, that I’ll explain fully in a separate post (that doesn’t quite yet work), which was actually the original approach, which is to isolate a single class, and try to identify which rows are in that class. This works out nicely on parallel machines, because you run tests for each class simultaneously, but this is not something you can do on a PC.
I’ve just applied my basic supervised image classification algorithm (see Section 1.2 of this paper) to an MRI image classification dataset from Kaggle, and a Skin Cancer classification dataset from Harvard. The MRI Dataset classification task is to classify the type of brain tumor, or absence thereof, given four classes. The accuracy for the MRI Dataset is consistently around 100% (using randomized partitions into training / testing datasets), and the runtime over 1503 training rows is 15 seconds (including pre-processing) running on an iMac.
I’ve also applied the supervised clustering algorithm (see the same paper above) to the MRI dataset, which has an accuracy around 94%. This would allow doctors to not only diagnose patients with great accuracy on a cheap computer, since the clustering step would also allow them to compare the most similar brain scans. Clustering the entire testing dataset of 376 rows in this case took about 10 seconds, running on an iMac. For example, the left most image above is an input image of a pituitary brain tumor, and the two images to the right of that are the images returned by the clustering algorithm, both of which also represent brains with pituitary tumors.
The downside to my approach is that the algorithm “rejects” a large number of rows from the testing dataset as outside of the scope of the training dataset (always on a blind basis, based upon only training data). Without getting too into details, you can soften the standard it uses to reject data, and if you do so, of course, the percentage of rows that gets rejected starts to decrease, though accuracy starts to suffer.
So what I’ve done for the Skin Cancer dataset is to allow a sliding scale of precision, that rejects fewer and fewer rows, and reports the classification prediction accuracy at each scale. This lets the user decide whether they want basically perfect confidence in their predictions, at the expense of rejecting a large portion of the testing dataset, or somewhere just beyond that, perhaps significantly so, if they’re more interested in bulk predictions than precision. For the Skin Cancer Dataset, this produces accuracies that range from 100%, with a rejection rate of 99.750%, to 85.750%, with a rejection rate of 0%, which is effectively unsupervised nearest neighbor. Note that I’ve consolidated all of the malignant classes into one class, leaving the benign class as the second class. I’ve also converted the dataset to grey scale, so it’s possible you’d get even better accuracy using full color, since from what I understand, color is relevant to classifying skin lesions. You could tweak these techniques, to, for example, reduce the rejection rate until it hits zero, whereas I’ve used a fixed number of iterations for simplicity, for now.
Finally, note that the Skin Cancer dataset contains not proper duplicates, but at times multiple photos of the same patient’s lesions, so as a temporary fix, I’ve randomly selected a subset of the total dataset, which means the issue shouldn’t occur too often, since the number of rows selected is 2000, out of roughly 10,000, and the number of duplicates is typically 2 or 3. I’ve already fixed this formally, by selecting exactly one image for each patient, and the accuracy was unchanged. I’m now working on the full dataset of one image per patient, which is taking some time to process, because it’s large, but the updated code should be up by tomorrow.
In general, this method should work for any single image classification dataset, where physical structure, or coloring, is indicative of disease. I will write a formal paper on the topic shortly.
The implications here are dramatic, and could democratize advanced healthcare –
All you need is a cheap laptop, the applicable dataset, and my software, and it seems, you can diagnose at least some conditions en mass, with great reliability, in just a few minutes. This would allow doctors to focus on only those patients that test positive, or have their results flagged as outside of the dataset, in this case reducing the caseload significantly. This is a big deal when you’re talking about a large number of people. By the same logic, this software allows you to reliably diagnose thousands of people, in a few minutes, again, with high accuracy.
You should run this on my updated algorithms, available on ResearchGate.
 , which is the minimum distance over which distinction between two vectors
, which is the minimum distance over which distinction between two vectors 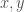 is justified by the context of the dataset. As a consequence, if you know
is justified by the context of the dataset. As a consequence, if you know  for which
for which 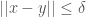 , you can thereby generate a cluster associated with the vector
, you can thereby generate a cluster associated with the vector  . This has remarkable accuracy, and the runtime is
. This has remarkable accuracy, and the runtime is  , where
, where  is the number of rows in the dataset, on a parallel machine. You can read a summary of the approach and the results as applied to benchmark UCI and MNIST datasets in my article, “
is the number of rows in the dataset, on a parallel machine. You can read a summary of the approach and the results as applied to benchmark UCI and MNIST datasets in my article, “ , and the mode class (i.e., the most frequent), has a density of
, and the mode class (i.e., the most frequent), has a density of  within
within 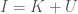 ,
,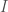 is the total information that can be known about a system,
is the total information that can be known about a system,  is your Knowledge with the respect to the system, and
is your Knowledge with the respect to the system, and  is your Uncertainty with respect to the system. In this case, the equation reduces to the following:
is your Uncertainty with respect to the system. In this case, the equation reduces to the following: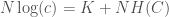 ,
, is the number of classes in the dataset,
is the number of classes in the dataset, 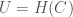 is the Shannon Entropy of the prediction cluster, as a function of the distribution of classes in the cluster.
is the Shannon Entropy of the prediction cluster, as a function of the distribution of classes in the cluster.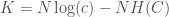 .
.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) scale, given
scale, given  rows of the MNIST Fashion Dataset. The effect of this is to require an increasingly high probability, and increasing confidence in your measure of that probability. The dataset is then broken into
rows of the MNIST Fashion Dataset. The effect of this is to require an increasingly high probability, and increasing confidence in your measure of that probability. The dataset is then broken into  random training and
random training and  random testing rows, done
random testing rows, done  times. The accuracy shown below is the average over each of the
times. The accuracy shown below is the average over each of the  at a certain point, is because there are no rows left that satisfy the threshold. The accuracy peaks at
at a certain point, is because there are no rows left that satisfy the threshold. The accuracy peaks at 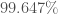 , and again, this is without any training step, so it is in fairness, an unsupervised algorithm.
, and again, this is without any training step, so it is in fairness, an unsupervised algorithm.
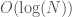 runtime algorithm using the code attached to my paper
runtime algorithm using the code attached to my paper 
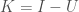 . I’ll explain how those values are calculated later, but you can look through the code to see they’re related to entropy and information theory generally. The equation states something that must be true about epistemology, which is that the sum of what you know about a system (
. I’ll explain how those values are calculated later, but you can look through the code to see they’re related to entropy and information theory generally. The equation states something that must be true about epistemology, which is that the sum of what you know about a system (

