Out of curiosity, I experimented with alternative normalization algorithms, and the results are basically the same as my core approach, which is to iterate through different digit scales, and run nearest neighbor, selecting the digit scale that generates the highest accuracy for nearest neighbor. The reason this works, is because you’re maximizing local consistency, by definition. The alternative approach, is to run a different algorithm, and test its accuracy, in this case, I ran a cluster prediction algorithm. Limited testing suggests it’s at best just as good, and possibly not as good, so given that nearest neighbor is incredibly fast when vectorized (i.e., O(number of rows)), there’s no practical reason to do otherwise.
You can find an example of the alternate code on Research Gate.
 , we would take the difference between adjacent range values as is, producing the vector
, we would take the difference between adjacent range values as is, producing the vector  . Then calculate
. Then calculate 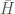 using that vector. Then, you sort the range values, in this case producing
using that vector. Then, you sort the range values, in this case producing 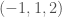 , and repeat this, and the degree to which
, and repeat this, and the degree to which  .
.