Introduction
Real world data is often observably consistent over small distances. For example, the temperature on the surface of an object is probably going to be roughly the same over distances that are small relative to its total area. Similarly, the average color in an image of a real world object generally doesn’t change much over small distances, other than at its boundaries. Many commonly used datasets are also measurably consistent to some degree, in that classifications do not change over relatively small distances. In a previous article, I noted that if your dataset is what I call, “locally consistent”, which means, informally, that classifications don’t change over some fixed distance, then the accuracy of the nearest neighbor algorithm cannot be exceeded.
In this note, I’ll again present the idea of local consistency, though formally, through a series of lemmas. I’ve also attached code that makes it easy to measure the classification consistency of a dataset, which in turns implies that you can say, ex ante, whether nearest neighbor will in fact be the best the algorithm for the dataset, in terms of accuracy. Finally, because nearest neighbor can be implemented using almost entirely vectorized operations, it would have at worst a linear runtime as a function of the number of rows in the dataset, on a sufficiently parallel machine.
Local Consistency
A dataset  is locally consistent if there is a value
is locally consistent if there is a value  , for each
, for each  , such that the set of all points for which
, such that the set of all points for which  ,
, 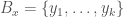 , has a single classifier, equal to the classifier of
, has a single classifier, equal to the classifier of  , and
, and  is non-empty, for all . That is, all of the points within are within
is non-empty, for all . That is, all of the points within are within  of , and are of a single class. We say that a dataset is locally consistent around a single point
of , and are of a single class. We say that a dataset is locally consistent around a single point  , if is non-empty.
, if is non-empty.
For reference, the nearest neighbor algorithm simply returns the vector within a dataset that has the smallest Euclidean distance from the input vector. Expressed symbolically, if  implements the nearest neighbor algorithm, as applied to , over , and
implements the nearest neighbor algorithm, as applied to , over , and  , for some
, for some  , then
, then  , for all
, for all  . Further, assume that if there is at least one
. Further, assume that if there is at least one  , such that
, such that  , then the nearest neighbor algorithm will return a set of outputs,
, then the nearest neighbor algorithm will return a set of outputs,  .
.
Lemma 1. If a dataset is locally consistent, then the nearest neighbor algorithm will never generate an error.
Proof. Assume that the nearest neighbor algorithm is applied to some dataset , and that is locally consistent. Further, assume that for some input vector , the output of the nearest neighbor algorithm, over , contains some vector  , and that has a classifier that is not equal to the classifier of , thereby generating an error. Since is contained in the output of the nearest neighbor algorithm, as applied to , over , it follows that
, and that has a classifier that is not equal to the classifier of , thereby generating an error. Since is contained in the output of the nearest neighbor algorithm, as applied to , over , it follows that  is the minimum over the entire dataset. Because is locally consistent, there is some nonempty set , that contains every vector
is the minimum over the entire dataset. Because is locally consistent, there is some nonempty set , that contains every vector 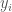 , for which, . Since is minimum, it must be the case that
, for which, . Since is minimum, it must be the case that  , for all . But this implies that
, for all . But this implies that  , which contradicts our assumption that the classifiers of and are not equal. Therefore, if we nonetheless assume their classifiers are not equal, then is not locally consistent, which leads to a contradiction, thereby completing the proof.
, which contradicts our assumption that the classifiers of and are not equal. Therefore, if we nonetheless assume their classifiers are not equal, then is not locally consistent, which leads to a contradiction, thereby completing the proof.
What Lemma 1 says is that the nearest neighbor algorithm will never generate an error when applied to a locally consistent dataset, since the nearest neighbor of an input vector is always an element of , which guarantees accuracy. As a practical matter, if the nearest neighbor isn’t within of an input vector , then we can flag the prediction as possibly erroneous. This could of course happen when your training dataset is locally consistent, and your testing dataset adds new data that does not fit into any .
Corollary 2. A dataset is locally consistent if and only if the nearest neighbor algorithm does not generate any errors.
Proof. Lemma 1 shows that if a dataset is locally consistent, then the nearest neighbor algorithm will not generate any errors. So assume that the nearest neighbor algorithm generates no errors when applied to , and for each , let 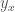 denote a nearest neighbor of , and let
denote a nearest neighbor of , and let  . Let
. Let  , and so each is non-empty. If more than one vector is returned by the nearest neighbor algorithm for a given , then include all such vectors in . By definition,
, and so each is non-empty. If more than one vector is returned by the nearest neighbor algorithm for a given , then include all such vectors in . By definition, 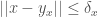 . Therefore, there is a value , for each , such that the set of all points for which , , has a single classifier, and is non-empty for all such , which completes the proof.
. Therefore, there is a value , for each , such that the set of all points for which , , has a single classifier, and is non-empty for all such , which completes the proof.
Corollary 3. A dataset is locally consistent around , if and only if the nearest neighbor algorithm does not generate an error, when applied to , over .
Proof. Assume that the nearest neighbor algorithm does not generate an error when applied to . It follows that there is some  , generated by the nearest neighbor algorithm, as applied to , over , for which
, generated by the nearest neighbor algorithm, as applied to , over , for which  is minimum, and the classifiers of and are all equal. Let
is minimum, and the classifiers of and are all equal. Let 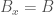 , and let
, and let  . Since, the classifiers of and are all equal, this implies that is locally consistent around .
. Since, the classifiers of and are all equal, this implies that is locally consistent around .
Now assume that is locally consistent around , and let be the output of the nearest neighbor algorithm, as applied to , over . It follows that is minimum over , and therefore,  . This implies that the classifier of equals the classifier of each , which completes the proof.
. This implies that the classifier of equals the classifier of each , which completes the proof.
Clustering
We can analogize the idea of local consistency to geometry, which will create intuitive clusters that occupy some portion of Euclidean space. We say that a dataset is clustered consistently, if for every , there exists some , such that all points contained within a sphere of radius (including its boundary), with an origin of , denoted  , have the same classifier as .
, have the same classifier as .
Lemma 4. A dataset is locally consistent if and only if it is clustered consistently.
Proof. Assume is locally consistent. It follows that for each , there exists a non-empty set of vectors , each of which have the same classifier as . Moreover, for each  , it is the case that . This implies that all vectors within are contained within a sphere of radius , with an origin of . Therefore, is clustered consistently.
, it is the case that . This implies that all vectors within are contained within a sphere of radius , with an origin of . Therefore, is clustered consistently.
Now assume that is clustered consistently. It follows that all of the vectors within have a distance of at most , from . Let be the set of all vectors within . This implies that for every , there exists a non-empty set of vectors , all with the same classifier, such that for all ,  . Therefore, is locally consistent, which completes the proof.
. Therefore, is locally consistent, which completes the proof.
What Lemma 4 says, is that the notion of local consistency is equivalent to an intuitive geometric definition of a cluster that has a single classifier.
Lemma 5. If a dataset is locally consistent, and two vectors 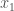 and
and 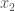 have unequal classifiers, then there is no vector
have unequal classifiers, then there is no vector  , such that
, such that 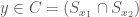 .
.
Proof. If the regions bounded by the spheres  and
and  do not overlap, then
do not overlap, then  is empty, and therefore cannot contain any vectors at all. So assume instead that the regions bounded by the spheres and do overlap, and that therefore, is a non-empty set of points, and further, that there is some
is empty, and therefore cannot contain any vectors at all. So assume instead that the regions bounded by the spheres and do overlap, and that therefore, is a non-empty set of points, and further, that there is some  , such that .
, such that .
There are three possibilities regarding the classifier of :
(1) It is equal to the classifier of ;
(2) It is equal to the classifier of ;
(3) It is not equal to the classifiers of or .
In all three cases, it follows that  , and
, and  , which leads to a contradiction, since the Lemma assumes that the classifiers of and are not equal. Since these three cases cover all possible values for the classifier of , it must be the case that does not exist, which completes the proof.
, which leads to a contradiction, since the Lemma assumes that the classifiers of and are not equal. Since these three cases cover all possible values for the classifier of , it must be the case that does not exist, which completes the proof.
What Lemma 5 says, is that if two clusters overlap as spheres, then their intersecting region contains no vectors from the dataset.
Corollary 6. If is locally consistent, then any clustering algorithm that finds the correct value of , for all , can generate clusters over with no errors.
Proof. It follows immediately from Lemma 5, since any such algorithm could simply generate the sphere , for all .
You can easily approximate the value of  for every row in a dataset using the code I’ve attached below, as applied to the MNIST Fashion Dataset, and it also generates the set for every row (it’s stored in the “final_rows” in the attached code). You can then count how many rows are locally consistent, which allows you to measure the classification consistency of the dataset.
for every row in a dataset using the code I’ve attached below, as applied to the MNIST Fashion Dataset, and it also generates the set for every row (it’s stored in the “final_rows” in the attached code). You can then count how many rows are locally consistent, which allows you to measure the classification consistency of the dataset.
Here’s a more formal PDF document that presents the same results:
