I noted in a footnote to my paper on magnetism (See, “A Unified Model of the Gravitational, Electrostatic, and Magnetic Forces“) that it’s strange that charge disperses along the path of least resistance, but I actually don’t think it’s strange at all anymore. The way charges work when you look closely is that they disperse in huge numbers, so if there is a least resistant / most efficient path, then most of those charges should take that path, not because of information ex ante, but just because it’s the path that allows the most charges to travel the furthest towards the opposite pole they’re all grasping towards.
Month: May 2021
A Note on Gravity
It just dawned on me again, that the structure of a mass should impact its gravitational field, as opposed to just its total mass –
This has to be the case, because imagine dividing the Earth in half and taking one half far away from the other.
Obviously not the same anymore.
So for a less extreme case where you simply alter the distribution of mass within its volume, you should get a different gravitational field, though it’s probably not noticeable at our scale of observation. Nonetheless, the idea makes sense. I think this is at the cutting edge of science (i.e., actually detecting gravity directly), but if you can do it, then this suggests that the field emitted should have a structure that is perhaps unique to the mass in question. So this might in turn might let us determine the structure of systems that are far away by simply detecting their gravity directly, and looking for patterns, which is again, not easy to do, but if possible, that could be really useful for cosmologists. Specifically, it would give insight into the internal distribution of mass within a system, which I don’t think you can discern otherwise –
You certainly can’t bounce a light off of a planet that’s light years away, but you might be able to detect its gravitational field.
You could start with experiments on Earth using mass, or perhaps the Earth itself, to measure experimentally how the distribution of mass within a system affects the resultant gravitational field, and then back out inferences from cosmological observations based upon the results obtained on or near Earth.
Perhaps you can even skip attempting to detect gravity itself directly, and instead pump a photon through the gravitational field in question, and measure its direction of motion, or frequency, probably both, to determine what impact the gravitational field had on the photon. Or you can leave a mass at a point, and measure its displacement due to the gravitational field in question. This of course might be even more difficult than simply detecting gravity directly, because you’re talking about really small changes to the momentum of a photon, or a mass, especially if you’re talking about changes due to gravity from another planet, as measured on or anywhere near Earth. This might however be realistic in space, sufficiently far from any planet, but you’re still left with the problem of winnowing down the source of a given gravitational field, and attempting to point (or otherwise orient) the instrument in question so that you only account that source. It’s just an idea and may be worse than simply using what I believe to be really new technology that can detect gravity directly, but in either case, the idea makes sense –
The signal contained in a gravitational field should tell you about the distribution of mass in its source, and that’s the real point of the idea, which is already implied by my work on gravity (See, “A Unified Model of the Gravitational, Electrostatic, and Magnetic Forces“), but I didn’t mention the point of backing out structure based upon the actual signal of a gravitational field, because it’s not important to the theory –
It’s applied science, not a theoretical consideration.
Whether you measure this using gravitational force carriers directly, or the effects of gravity on some measuring device, is a question of implementation, and I’m in no position to offer real advice on that. However, because gravity cannot be shielded against, or insulated, if you’re looking for a particular gravitational field, it should exist along a straight line.
New Copyright Policy
I hereby release the following works into the public domain (the “Release”):
All of the articles on all of my wordpress blogs, including but not limited to Information Overload, and Principia Principalis;
All of the articles on my ResearchGate and my SSRN homepages.
Sketches of the Inchoate (currently available on this site);
VeGa (currently available on this site).
(A) (Together, the “Written Works”);
And,
All of my music, that is published anywhere, in any form, including but not limited to those recordings on SoundCloud;
(B) (collectively, the “Music”).
To be clear, the Release does not apply to any underlying algorithms or other software related to the Written Works, or described in the Written Works, and instead relates to only the text of the Written Works themselves, which can be reproduced, printed, excerpted, and modified, in each case without any restrictions, provided any modifications are reasonably identified as modifications to the original.
I reserve all rights in the underlying algorithms, and the algorithms may not be used for commercial purposes without my express prior written consent.
The Music may not be used for commercial purposes without my express prior written consent, but is otherwise released into the public domain, for unrestricted reproduction, performance, modification, and rearrangement, provided any rearrangement is reasonably identified as a rearrangement of the original.
Provided further, that the Release in all cases requires that my name (Charles Davi) be accredited and visible in some reasonable manner as the author of the related Article or Music.
The Release and related statements written above (the “New Copyright Policy”), hereby render void any and all other statements, writings, or verbal agreements, related to my intellectual property in the Written Works and the Music, whether published anywhere, or otherwise articulated, prior to the date hereof (May 31, 2021).
I am the sole owner of all intellectual property in the Written Works and the Music, and no other person or party has any authority at all, or property at all, under any circumstances, including in the event of my death or incapacity, with respect to the Written Works or the Music.
The New Copyright Policy may not be amended in any circumstances, other than by yet another policy written and published publicly by me, and no other person or party has any right to amend or supplement the New Copyright Policy, including in the event of my death or incapacity.
Therefore, as the sole owner of the intellectual property in the Written Works and the Music, I hereby release the Written Works and the Music into the public domain, subject to the limitations described above.
In the event that the New Copyright Policy described above is found to be inconsistent with U.S. law, by a court of competent jurisdiction, or such court would otherwise cause the Written Works or the Music to be removed from publication, censored, or pass in property to some party other than myself (each, a “Trigger Event”), then the Written Works and the Music are to be released into the public domain without any restrictions or other limiting terms at all, with all rights and terms necessary to allow for the Written Works and the Music to be released into the public domain.
For the avoidance of doubt, the New Copyright Policy applies, as of the date hereof, unless a Trigger Event occurs, in which case the Written Works and the Music are released into the public domain without any limitations, subject only to those terms required by applicable U.S. law to effectuate a release into the public domain.
All Algorithms
Below is a link to all of my algorithms as of today:
https://www.dropbox.com/s/ykrw4ncw1hqfci9/ALL_C_DAVI_ALGOS_1%202.zip?dl=0
Obviously, the same license applies, and for clarity, these algorithms may NOT be used for commercial purposes.
Quantifying the Scientific Method
This morning I realized that you can consider error in terms of uncertainty rigorously. I explained the mathematics of this in a previous article, showing that you can associate the distance between two vectors 

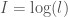
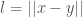




Separately, I also showed that there’s a simple equation that relates information, knowledge, and uncertainty, as follows:

Intuitively, your uncertainty with respect to your prediction function

What this implies is that when your error is zero, your uncertainty is also zero, and moreover, grows as an unbounded function of your error.
The total information of a static system should be constant, and so the value 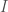


For some constant 
Because we have assumed that

What’s interesting about this is that this set of equations together implies that,
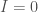
Moreover, for all non-zero error, your knowledge is a negative number.
At first, I was a puzzled by this, but upon reflection, it makes perfect sense, and is consistent with the scientific method generally:
If you have no error, then you know nothing;
If you have any error at all, then you know you’re wrong.
This is in contrast to the knowledge that is possible when dealing with systems that have components that can be identified, and defined with certainty, which I discuss in the articles linked to above. In this case, what you’re measuring is your absolute uncertainty given only your error with respect to some true underlying function over some domain. It is therefore simply not the case that this would allow you to make any claims about the behavior of the function outside of that domain, absent other assumptions limiting the possibilities for the underlying function. Said otherwise, at best, in the absence of additional assumptions, you know nothing, in that you’re not wrong over that domain, but you have no knowledge about
On Classification and Prediction
It dawned on me that I think I’ve exhausted the topics of classification and prediction in A.I., and here’s why:
Either a dataset is locally consistent, in which case, my core algorithms will solve it, in polynomial time;
If it’s not locally consistent, then you use interpolation among the features, perhaps of a very high degree, but it doesn’t matter, because the bottom line is, even a neural network is a function that maps an input vector to a classification –
So, you can approximate that neural network function using a polynomial, since it’s a function from 
So, I’m turning entirely to my work in physics and A.I., which has applications to image processing, and if I have time, I’ll also do some work on NLP, because I have tons of unpublished research on the topic.
Letter to the Congressional A.I. Caucus
May 23, 2021
Re: Anticompetitive Practices in the Market for A.I. Software
Dear Members of Congress,
I’m currently an entrepreneur looking to raise funding to market and lease my A.I. software, though before that, I worked in financial services, for eight years, most recently at BlackRock, and McDermott Will & Emery before that. I received my J.D. from New York University School of Law, and B.A. in computer science from The City University of New York. I published articles in refereed mathematics journals as an undergraduate, won national research contests in computer science, again as an undergraduate, and wrote for many years in The Atlantic as a young professional, about finance and economics, in my free time.
I’m emailing you because I believe there are very serious and extremely obvious anticompetitive practices in the market for A.I. software, that I’ve explained below.
Background
The most basic prediction algorithm in A.I., known as the, “nearest neighbor algorithm”, which I did not develop, is actually the best algorithm for many real world problems in A.I. (see attached, “Analyzing Dataset Consistency”).
This is not a matter of pride –
I did not come up with this algorithm, and I don’t know who did. It has been around for decades, and in any case, it is certainly widely known, and even has a Wikipedia page:
https://en.wikipedia.org/wiki/Nearest_neighbor_search
This is also not a subject of debate –
The math is absolute, but even if you don’t understand the theory, you can simply download and run the software to see that it works (see Section 1.1., example, “MNIST Numerical Dataset” of, “Vectorized Deep Learning”, attached).
The intuition for the nearest neighbor algorithm is straightforward: if A and B are the most similar items in scope, and you know what A is, then you should be able to predict what B is. For example, if A is a picture of a cat, and picture B is most similar to A, out of all other pictures in scope, then B should also be a picture of a cat. Of course, implementation is not quite this simple, but it’s not that complicated either, and this really is the basic idea.
The nearest neighbor algorithm reduces many real world problems in A.I. to something that some high school students would have no problem understanding and coding. Yet, this algorithm is never discussed, in my experience, let alone used. In fact, I’ve never even seen it discussed in an A.I. tutorial, despite the fact that it is not only incredibly simple, but also incredibly powerful.
So the natural question is, why isn’t the industry making use of what is often the best approach to many basic problems in A.I.?
I believe the answer is not so good.
It is my belief that the tech sector is profoundly corrupt, and recent events in the sector should convince you that this is the case, with espionage, anticompetitive behavior, and probably worse, all common practice in the sector. But even so, why would a market of this scale, that is ostensibly sophisticated, make use of inferior techniques?
I believe the answer is that firms in the market profit from the amount of time it takes to perform a task on their servers –
They are therefore economically disincentivized to allow for efficiency.
Said otherwise, the longer a program takes to run, the more they get paid. So they don’t want the best solution to a problem, they want the worst one, because that’s the one that takes the longest time to run, generating the most revenue, and the biggest bills for their clients.
The next question is, why do clients put up with it? Because they don’t have a choice, and that’s what an oligopoly is –
A market so small, dominated by so few firms, that the market stops making economic sense, with price and term fixing, and all the rest. This is precisely why this type of conduct is a criminal offense in the United States, because it stifles competition and innovation.
To be perfectly clear, it is my opinion that firms in the tech sector are actively suppressing the most efficient software in A.I. (which includes but is not limited to the nearest neighbor algorithm), because they profit more from the least efficient software. This must be the case, because the simplest software in all of A.I. (i.e., the nearest neighbor algorithm) cannot be beat in terms of accuracy for many real world problems, yet it’s never discussed, let alone used, to my knowledge and in my experience.
Conclusion
Again, it is public knowledge that the tech sector is an oligopoly, and this fact is now the subject of multiple enforcement actions at the state and federal level. Common sense suggests that this is exactly the type of economic environment where an otherwise unthinkable anticompetitive ruse would be possible. Moreover, these are gigantic companies that plainly run an oligopoly, so the idea that they wouldn’t suppress innovation for commercial gain is beyond naive, and is just not how economies, markets, or people function.
It is my honest opinion that the market for A.I. is promoting nonsense solutions in one of the most important sectors to the future of this country, A.I., so that a handful of firms can maintain market share and revenues. This is obviously bad for the American economy, as innovation will be effectively cut off domestically, and flourish abroad, which at some point, will create national security risks, and probably already has, given that as I noted above, this basic technique has been around for decades.
This type of otherwise unbelievable outcome regrettably has recent precedent in the U.S. –
Bernie Madoff ran a multi-billion dollar, imaginary business, that somehow avoided regulatory scrutiny, despite reportedly never executing a single trade. This is something that even the most basic regulatory inquiry would have uncovered. I’ll also note that the SEC ignored a mathematician that told them that it was mathematically impossible for Bernie Madoff to be making the returns he claimed to be making. It turns out, this was correct.
I am telling you, as a mathematician, that it is mathematically impossible to beat the nearest neighbor algorithm for many real world problems. This implies quite plainly that the market for A.I. software is distorted by collusion and oppression, likely doing harm to the American economy on a massive scale, and no one’s doing anything about it.
For a neutral introduction to A.I., I’d recommend this video from MIT, which discusses early advances in A.I., from 1961, that will give you a sense of how advanced A.I. really is, now that we’re sixty years from this already astonishing technology:
The fact that these ideas have been around for decades raises other issues:
It turns out that the nearest neighbor algorithm, again the most basic prediction algorithm, theoretically has perfect accuracy on certain datasets, which often translates into nearly perfect accuracy in practice. So now imagine what the truly most efficient solutions in A.I. are capable of; Think about how much data these companies have about basically every American, including children, regarding their interests, their relationships, their personal conversations, and therefore their most intimate experiences, and even their health; What are they doing with all of that data and predictive power? I’m betting it’s nothing good, given what I’ve outlined above.
This kind of predictive power likely allows them to predict things about people, including possibly information about their health, that they would be otherwise unable to know without express consent from the person in question. So how could it be acceptable, or maybe even legal, for a company to predict something about you, without your consent, that they would otherwise have to ask you directly? Think about the implications for diversity, e.g., if you could predict someone’s race, religion, or orientation, without asking them directly. Think about the implications for disabled or otherwise sick people, if e.g., an employer could predict health issues about their employees or applicants, without asking them directly. These are glaring and obvious problems, that threaten the American public, and are going totally unaddressed by Congress, which is, with all due respect, disgraceful.
Please let me know if you have any questions regarding these matters, as I’d be happy to answer them.
Note I’ve posted a copy of this letter on my research page, and plan to share it with members of the press.
Best Regards,
Charles Davi
On Complexity of Motion
I’m currently working on software that will control the motions of a simple, single joint, which should be ready in the next few days.
I’ve thought quite a bit about the issue, and I’m again attacking the problems from first principles, building a new model and theory of observation and control.
And it dawned on me that you want motions to be as simple as possible, so that a human observer can anticipate those motions –
That is, you don’t want a robot to be physically unpredictable.
You can implement this by selecting sequences of motion that have low complexity, and that are, e.g., periodic, symmetric, etc.
That is, if you have a choice among a set of possible gestures that all achieve the same end state, select the gesture with the lowest complexity.
I’ve said exactly this before, in the context of entropy and variance, but it dawned on me that I’ve got algorithms that test for periodicity quite quickly, which should also work for this purpose.
To test for symmetry, set the codes for the motions so that one set of symmetrical gestures (e.g., a left hand) is 1 through N, and the other corresponding set of gestures (e.g., a right hand) is N+1 through 2N. If you have both up and down motions, then use -N through N (left) and -(N+1) through -2N, and N+1 through 2N (right) and take the absolute value of the instructions.
Then take the difference between adjacent entries in the sequence of motions, and the closer you are to N on average, the more symmetrical the motions will be. That is, if the difference between adjacent motions is approximately N, on average, then each motion is followed by its corresponding image under the symmetry in question.
This would, for example, in the case of raising both arms, cause the left and right arms to be alternately raised incrementally, and if the increment in time is small enough, it will appear as if the left and right arm are being raised in tandem. That is, the instruction vector will consist of alternating left right left right codes, each of which is the image of the next under some symmetry.
This could be implemented by taking an instruction vector that achieves the goal state, and then permuting it, selecting the sequence that minimizes complexity. Permutations are vectorized in Matlab / Octave.
Here’s a simple outline of an algorithm that should generate smooth motion from some initial state to a goal state:
- Take the difference between the initial state and goal state, delta_T;
- Take the difference between the initial state and the state achieved by applying one instruction (on average), delta_mu;
- Set the length of the instruction vector proportional to l = delta_T/delta_mu;
- Use a Monte Carlo simulation to generate a matrix of instruction vectors of length l;
- Select the least error vector (compared to the goal state);
- Remove any pairs of redundant instructions (e.g., +N followed by -N, anywhere in the vector).
- Set l to the new resultant length;
- Run the Monte Carlo simulator again, using the new length;
- Select the least error vector;
- Permute the least error vector, generating a matrix of instruction vectors;
- Select the lowest complexity vector.
Another Note on Monte Carlo
It just dawned on me watching an airplane fly, imagining a system that could design itself, in the sense that it would adjust its shape to account for, e.g., aerodynamics, you would need to first unpack the state space of possible configurations for the object. This is not the same as a goal-oriented state space algorithm, since you’re not looking for a known end state (e.g., a particular configuration), but are instead trying to unpack the set of possible configurations. Then, you would traverse that unpacked state space, optimizing for some variable, finding the orientation that minimizes / maximizes or otherwise best satisfies the constraints you have in mind.
In a previous article, I introduced a Monte Carlo optimization algorithm, that I now realize can be tweaked to perform exactly this type of state space unpacking function:
1. Evaluate some large number of possibilities using a Monte Carlo seed function;
2. Cluster the resultant possibilities, and for simplicity, let’s assume each possible outcome is represented as some vector;
3. Then, run the Monte Carlo seed function again;
4. Among the new outcome vectors, find the ones that are not within delta of the previous round, and allocate more capacity to those seed values, possibly all of the capacity (by definition, these outcomes are novel in the context of the known state space);
5. Repeat this process for some preset number of iterations, or until you no longer find novel outcomes.
Sonata for Harpsichord and Cello
I’ve written a sonata for Harpsichord and Cello, and I’m pretty sure I corrected all the counterpoint errors, so this should be the final version, and the mix is quite good.
