Introduction
I’ve been exploring notions of physical multiplicity for years, and I think you can make rigorous sense of it, using the ideas I’ve already developed in physics. Specifically, I think a multi-verse is fine, and in fact, you can imagine multiplicity expressed through a space that actually exists, where all possible outcomes from a given moment into the next, are actually physically real. Though this implies a question:
How are they arranged in that space?
As stated in a previous note, as a far as I know, multiplicity of outcome is real, given the same initial conditions, since collisions require only conservation of momentum (assuming nothing else changes in the collision). So given a moment in time, all future outcomes would be physically extant in the space of time itself, which would imply a space that grows, but is fixed at all generated points. That is, you’d have a tree that produces from inception, all possible next states. Instead, I think you also need a source that generates basically the same set of initial conditions over and over, and this would be like the Big Bang on repeat, with no material differences between proximate instances. This would cause mass to move not only through Euclidean space, but also through the space of time itself. Creating a space that is at any fixed point, basically the same forever, but nonetheless not truly fixed, with particles that have a velocity in both physical space, and time, entering, and leaving, onto the next, evolving as they progress through the space of time.
We can therefore imagine a line through the space of time itself, where nothing changes, because all exchanges of momentum net to zero, causing no change at all to the entire Universe, along that line. That is, this is the freak outcome Universe where every exchange of momentum nets to zero change, producing a static portrait of inception itself –
It’s the coin that always lands on its side, forever.
Imagine this as a line through a plane, with increasingly disparate outcomes at increasing distances from this line –
This is all you need to imagine the space of time, organized in the plane.
Dark Energy
Now imagine gravity and charge diffuse over both space and time. For if they instead diffuse over only space, then you end up with a law of gravity, e.g., that decreases in strength as a function of linear distance (just use basic trigonometry, assuming a constant rate and distribution of emission of force carriers projected towards a line of increasing distance from a point origin of the force carriers). This is, of course, wrong, because gravity obeys a square law of diffusion. So now instead assume that gravity diffuses over both time and space –
You end up with a square law of diffusion, which is correct. This in turn suggests the possibility that both gravity and charge are emitted through the space of time itself, in addition to Euclidean space. However, if this is the case, then it poses a related problem:
It implies that identical masses would be positioned proximately to each other in the space of time itself, subject to gravity. They would therefore attract each other, through gravity, which could literally cause a collision between two physically proximate moments in time. Since this doesn’t seem to happen, there must be a mechanism that ensures this doesn’t happen, though I think dark energy could be the result of gravity from proximate outcomes in time (note we wouldn’t be able to otherwise interact with the associated mass). That is, if dark energy exists at a point, it’s because there’s mass at that point in space, at a proximate point in time, but not in our time, causing the appearance of inexplicable gravity, that is unassociated with any mass. So if this is correct, there should be trace amounts of inexplicable gravity basically everywhere. Testing for this on Earth probably won’t work, because the Earth’s gravitational field is too dominant. So, put a device in space far enough from Earth and any other planet, and attempt to detect gravity that doesn’t appear to have an origin from any known mass.
Antigravity
You can posit forces to make sure that there’s no meaningful intrusion of mass from one moment in time into the next, which obviously doesn’t happen often at a large scale, otherwise we’d notice, though it is possible for spontaneous emergence and disappearance of energy at very small scales of time and space. For example, imagine a force of repulsion between masses, which as far as we know, doesn’t exist in our Universe, since it would be antigravity. However, it would serve the role well, because it would prevent large scale intrusions of mass crossing from one moment in time to the next, which as noted, plainly doesn’t happen. It would also complete the symmetry of gravity, which is anomalous in the context of charge and magnetism, in that there’s only attraction. Because light interacts with gravity, by analogy, we could posit that light interacts with this force, which would in turn prevent material intrusions of light as well.
The argument above suggests that antigravity obeys a square law of diffusion as well, which implies that antigravity would emerge in our Universe, basically everywhere, without any associated mass. However, because there’s no evidence of repulsion between masses, in order for antigravity to make sense, antigravity cannot cause acceleration in Euclidean space, and only acceleration in time. That is, gravity accelerates mass in only Euclidean space, as an attractive force, and antigravity accelerates mass in only the space of time, as a repulsive force. Finally, imagine the plane described above as a lattice of masses. Any mass that moves in any direction due to repulsion will be repelled in the opposite direction by some other mass, preventing any material change in relative positions in time, as they all progress through the space of time itself, their relative positions basically fixed.
Complex Length
Because we can’t physically measure complex numbers, it is at least sensible that distance in time actually has complex units, since we don’t experience and cannot measure movement in the space of time, we can instead only measure physical change in Euclidean space, as a proxy for actually traversing the space of time itself. Moreover, the mathematics also implies that time itself has complex units (see Footnote 7 of, A Unified Model of the Gravitational, Electrostatic, and Magnetic Forces).
Multiplicity, Time, and Waves
I’ve argued that multiplicity and waves are physically related, and this makes perfect sense, because waves are by definition a distribution over some space. Now consider the idea of not thermodynamic reversibility, but real mathematical reversibility, and consider it in the context of time –
How many initial conditions can give rise to the same final outcome?
Because conservation of momentum is typically the only constraint for collisions, the answer is an infinite number of initial conditions. So now imagine moving backwards through time, from a given state of a system, to its possible prior states, and what do you have?
A wave.
So this suggests at least the possibility that the transition from a point particle to a wave is the result of a change that flips a switch on the direction of time itself, causing a particle to propagate forwards through time, as if it were propagating backwards.





![v = [M1(:) M2(:) M3(:) M4(:)]](https://s0.wp.com/latex.php?latex=v+%3D+%5BM1%28%3A%29+M2%28%3A%29+M3%28%3A%29+M4%28%3A%29%5D&bg=ffffff&fg=444444&s=0&c=20201002)
 discrete chunks of energy. All systems must therefore be a subset of this total energy, and since we’re concerned only with total energy, let’s assume that there’s no order in which the particular chunks of energy are selected. This would reduce the number of possible instances of a system that consists of
discrete chunks of energy. All systems must therefore be a subset of this total energy, and since we’re concerned only with total energy, let’s assume that there’s no order in which the particular chunks of energy are selected. This would reduce the number of possible instances of a system that consists of  chunks of energy to
chunks of energy to  . You would then remove physically impossible energy levels from this set, which is obviously not trivial, but the point remains, that there must be such a distribution, if the total energy of the Universe is finite, and energy is itself quantized. That is, there are only a finite number of
. You would then remove physically impossible energy levels from this set, which is obviously not trivial, but the point remains, that there must be such a distribution, if the total energy of the Universe is finite, and energy is itself quantized. That is, there are only a finite number of  of them. Some energy levels might not be physically possible, and we remove those.
of them. Some energy levels might not be physically possible, and we remove those.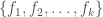 , and a set of positional offsets
, and a set of positional offsets  , where each
, where each 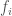 is a proper frequency, and each
is a proper frequency, and each  is the distance from the starting point of the wave to where frequency
is the distance from the starting point of the wave to where frequency 