In a previous research note, I introduced a method of quickly calculating an expectation value for the intersection count between any two given sets randomly selected from a family of sets. I’ve been doing work on the MovieLens dataset, and though I’ll soon post a more fulsome research note on the matter, I realized that the expected intersection calculation can be used to measure how much mutual information is contained on average between vectors in a dataset.
For example, the MovieLens dataset consists of around 200,000 movies rated by 610 users. However, a given user generally rates only a small fraction of those movies. We could simply take the entire dataset, but because it’s 200,000 dimensions, this will impact performance, and because each user doesn’t generally rate all of the movies, we’re probably doing far more work than is necessary. That is, we can almost certainly find a subset of those 200,000 dimensions that will give us enough information to meaningfully analyze the dataset.
The solution I’ve come up with is to sort the movies in the order of how many ratings they receive. That is, the top of this list is the movie that was rated by the most users. This is not necessarily the most popular movie, but rather, the movie that the most users took the time to rate.
As we proceed down this list, the probability that a given user rated the movie in question declines. As a result, each movie contributes less and less to the information about the dataset as we move down the list, simply because, by definition, fewer users have reviewed it.
We can then, for example, take a subset of the original dataset that corresponds to the top 100 movies in terms of their review count. Again, these are not necessarily the 100 most popular movies, but are instead the top 100 movies in terms of how many people reviewed them.
Even though these are the most rated movies, it’s still possible that the resultant subset of the dataset contains missing data. That is, just because a movie is frequently rated, doesn’t mean that all users rated it.
If we shape the dataset as a data matrix where each row corresponds to a user, and each column in a given row contains the rating the user gave to a particular movie, then we can then test which column entries are non-zero (i.e., non-empty), which will produce a binary matrix, which we can then feed to the expected intersection algorithm. This will calculate the expected number of overlapping, non-empty entries between any two rows from the dataset.
This is, therefore, a measure of the number of overlapping dimensions we’re expected to have between any two vectors from the dataset (i.e., any two rows from the data matrix).
We can then iterate the number of top movies sampled, and then measure the expected intersection count for each resultant subset of the dataset, which will allow us to measure how much information we’re getting in return for adding dimensions to our dataset. Below is a chart showing the expected intersection count for the MovieLens dataset as a function of the number of dimensions, where dimensions were added in the order of their rating count (i.e., dimension one is the most rated movie).

Dimension Compression
There is, however, no objective stopping point to this process. That is, the expected intersection between dimensions will continue to increase as we add more dimensions, and though we can measure the derivative of this function, there’s no obvious point at which we can say, this is the “right” amount of overlap between dimensions.
We can, however, apply my categorization algorithm (or some other categorization, or clustering technique) at each iteration, measure the entropy of the categorization, and find the number of dimensions that generates the greatest change in the structure of the categorization.
This is exactly what my core categorization algorithm does, except in that case, entropy is measured as a function of the level of distinction, 
So in short, we sort the dimensions of a dataset by frequency as described above (i.e., the most commonly used dimensions go first), and begin by categorizing the data using only the most common dimension (or some other small number of dimensions), and measure the entropy of that categorization. Then, we add the next dimension, categorize the dataset using those dimensions, and measure the entropy of the resultant categorization. We repeat this process up to a predefined maximum, which will presumably depend upon performance constraints. So if the machine in question can handle the full dimension of the dataset, then we can probably iterate up to that full number of dimensions.
Note that at each iteration, we let the categorization algorithm (or other clustering technique) run to fruition, producing a complete categorization of the dataset using the number of dimensions in question.
By selecting the number of dimensions that generates the greatest change in the entropy of the categorization structure, we will select the number of dimensions that unlocked the greatest amount of structure in the dataset – i.e., the most relevant dimensions of the dataset.
Now, it would be fair to say that this process actually requires more work than simply categorizing the data once, using all of the dimensions in the dataset, and that is correct. That is, by definition, this process will repeatedly categorize the dataset for every dimension from 1 up to and including N (i.e., the actual number of dimensions). This is obviously more work than simply categorizing the dataset once using all N dimensions.
However, we can use the expected intersection to select a representative subset of the dataset, and apply this process to that subset, rather than the entire dataset. Specifically, we can randomly select vectors from the dataset, and test the expected intersection for that subset of vectors, and iteratively increase the number of vectors selected until we hit an expected intersection count that is sufficiently close to the expected intersection count for the entire dataset (and sufficiently stable as we add more vectors). That is, we add vectors until the expected intersection for the subset is close to, and stable around, the expected intersection for the entire dataset.
We can also test the individual frequencies of the dimensions from this subset of vectors during this process, which is also produced by the expected intersection function. Specifically, we can calculate the norm of the difference between the frequencies of the subset and the frequencies of the entire dataset.
This ensures that we have a number of vectors with dimensions that overlap approximately as much as the entire dataset (as measured by the expected intersection count), and dimensions with approximately the same frequencies of usage as the original dataset (as measured by the frequencies of the dimensions calculated by the expected intersection function in the “weight vector”).
Put together, this will allow us to find the optimum dimension for the dataset without having to repeatedly categorize the entire dataset. Finally, note that we could apply this process to any resultant data structure capable of generating a measure of entropy. For example, we could apply this process to my “generate data tree algorithm“, which generates a tree of subcategories of a dataset, measuring the entropy of the resultant data tree after each iteration over the dimensions.
Measuring Missing Information
We can also use these ideas to get a sense of how complete a dataset is by measuring the expected intersection on the full dataset, and dividing by the number of dimensions in the full dataset. For example, if the dimension of our dataset is 100, and the expected intersection over the full dataset (as described above) is 10, then the measure would in this case be .1, or 10%. This means that, on average, only 10% of the dimensions of the dataset will be relevant when comparing two vectors from the dataset, since only 10% of them are expected to overlap.
In the extreme case when the expected intersection is 0, then in some sense, we don’t really have a dataset – we have collection of independent observations. For example, if our dataset consists of two vectors (1,2,{}) and ({}, {}, 1), where {} indicates a missing entry, then there is no overlap between the dimensions of those two vectors. This means that without any other information about what the vectors represent, we can’t compare them. In contrast, if the two vectors were (1,2,3) and (4,5,1), then we can of course compare every dimension of the vectors.
Since the expected intersection allows us to form an expectation value as to the number of overlapping dimensions between any two vectors in a dataset, we can in turn measure the completeness of the dataset.
In the language of the theory of AI that I’ve been developing, I would say that this method allows us to measure the extent to which a dataset provides its own context. When the ratio of the expected intersection and the dimension of the dataset is 1, then the dataset provides the maximum context possible without any exogenous information about the dataset. When the expected intersection is zero, then the dataset provides no context, and is instead, ex ante, assuming no other prior information, a collection of unrelated observations.
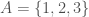 and
and  , then the “distance” measure on those two sets would be
, then the “distance” measure on those two sets would be 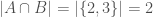 .
.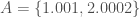 and
and  . If
. If  , then
, then 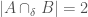 , since
, since  and
and 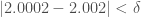 . I developed this operator in the context of color processing, where you might want to take the intersection count between two sets of colors, and say close enough is good enough to constitute a match. For an explanation of how we determine the appropriate value of
. I developed this operator in the context of color processing, where you might want to take the intersection count between two sets of colors, and say close enough is good enough to constitute a match. For an explanation of how we determine the appropriate value of 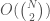 calculations, where
calculations, where  is the number of items in the dataset. The calculation of ordinary intersection can be vectorized trivially, so this is by no means intractable. But, using set theory, we can approximate this number using
is the number of items in the dataset. The calculation of ordinary intersection can be vectorized trivially, so this is by no means intractable. But, using set theory, we can approximate this number using  calculations, which on a low-end device, could mean the difference between an algorithm that runs in a few seconds, and one that runs in a few minutes.
calculations, which on a low-end device, could mean the difference between an algorithm that runs in a few seconds, and one that runs in a few minutes. items, then we could use the names of the actual products (assuming they’re distinct), the numbers
items, then we could use the names of the actual products (assuming they’re distinct), the numbers  through
through  through
through  ,
,  bits, or any other set of
bits, or any other set of 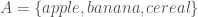 . Any dataset that consists of sets like
. Any dataset that consists of sets like  , then
, then  , whereas if
, whereas if  , then
, then  , and so we can reasonably say that
, and so we can reasonably say that  are more similar to each other than
are more similar to each other than  . In general, the larger the intersection count is between two sets, the more similar the two sets are.
. In general, the larger the intersection count is between two sets, the more similar the two sets are. items, then we can represent the dataset as a binary matrix of
items, then we can represent the dataset as a binary matrix of  , then set
, then set  contains item
contains item  , and otherwise, the entries are
, and otherwise, the entries are  .
. and
and  , and there are
, and there are 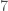 seven items in the dataset, then we would represent
seven items in the dataset, then we would represent  and
and  .
.


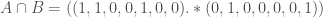
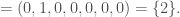


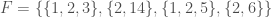 . The union over all of the sets in
. The union over all of the sets in  is
is  , and every item in the union occurs once in the dataset, except for
, and every item in the union occurs once in the dataset, except for  , which occurs four times. If we randomly select a set from
, which occurs four times. If we randomly select a set from  , since
, since  , and the corresponding weights are
, and the corresponding weights are  . The intersection count between
. The intersection count between  and the expected set over
and the expected set over  , as weighted by the elements of
, as weighted by the elements of 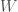 , which is in this case
, which is in this case  .
. . Then, we apply a function that maps the elements of that set to the elements of
. Then, we apply a function that maps the elements of that set to the elements of 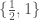 . Then, we take the sum over that set, which I’ve defined as the intersection count between the set in question and the expected set, which is in this case
. Then, we take the sum over that set, which I’ve defined as the intersection count between the set in question and the expected set, which is in this case  .
. elements. If we calculate the average intersection with the expected set for each of the four sets, it comes out to
elements. If we calculate the average intersection with the expected set for each of the four sets, it comes out to  elements. On a percentage-wise basis, there is a significant difference between these two values, but nonetheless, this method allows us to generate a reasonable approximation of the average intersection count between every pair of elements with only
elements. On a percentage-wise basis, there is a significant difference between these two values, but nonetheless, this method allows us to generate a reasonable approximation of the average intersection count between every pair of elements with only  calculations, where
calculations, where  seconds per image (on average) from start to finish (including all pre-processing time) to classify the dataset of images below. Note that this is the amount of time it took per image to train the classification algorithm, as opposed to the amount of time it would have taken to classify a new image after the algorithm had already been trained. Like all of my algorithms, these algorithms have a low-degree polynomial runtime.
seconds per image (on average) from start to finish (including all pre-processing time) to classify the dataset of images below. Note that this is the amount of time it took per image to train the classification algorithm, as opposed to the amount of time it would have taken to classify a new image after the algorithm had already been trained. Like all of my algorithms, these algorithms have a low-degree polynomial runtime.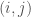 region of the image contains a boundary, then the
region of the image contains a boundary, then the 




 accurate, meaning all categories were perfectly consistent with the hidden classifiers. For the handwritten character dataset, the categorization algorithm had an accuracy of
accurate, meaning all categories were perfectly consistent with the hidden classifiers. For the handwritten character dataset, the categorization algorithm had an accuracy of 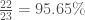 , since exactly
, since exactly 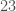 was inconsistent with the hidden classifiers.
was inconsistent with the hidden classifiers.





