I published some code that iteratively applies Nearest Neighbor until you create a loop. That is, you run Nearest Neighbor on its on output until you return the same row twice. Symbolically, if 



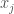
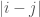
But it just dawned on me, if you don’t allow it to create a loop, and instead delete any row that produces a loop, and apply it again, until you find a unique output, it will force you to iterate through the entire dataset, quantizing the distance between a given starting row, and all other rows. If you do this for a population of genetic sequences, e.g., using human genomes, you can then define the distance between a member of a given population, and all other populations, globally. If you do this repeatedly, you will create a distribution of distances from one population to all others. So if for example you start with a large group of Chinese people, and then apply Nearest Neighbor, using a subset of the entire world population as your dataset (i.e., all major geographies), you will construct a quantized distribution of distances from Chinese people to all other people, which will of course probably iterate through a large number of Chinese people before moving on, but it will eventually move on.
This distribution will also of course create averages, allowing you to say that, e.g., on average Chinese people are a quantized distance of one, two, etc., from populations A,B, and so on. It will also allow you to identify anomalies, since everyone will fall within that distribution, at some distances from the averages. This is now doable, because of the IGSR Dataset, and I’m just starting to download files, which are extremely large, so this will take some time.
If you can figure out a mapping across species, you could in theory apply this process to the entire set of known organisms, creating a distance metric that covers all species.
